变分自编码器
一般用于生成对特定数据的,有变化的新数据。例如针对特定图片生成一个略有不同的新图片。
概要
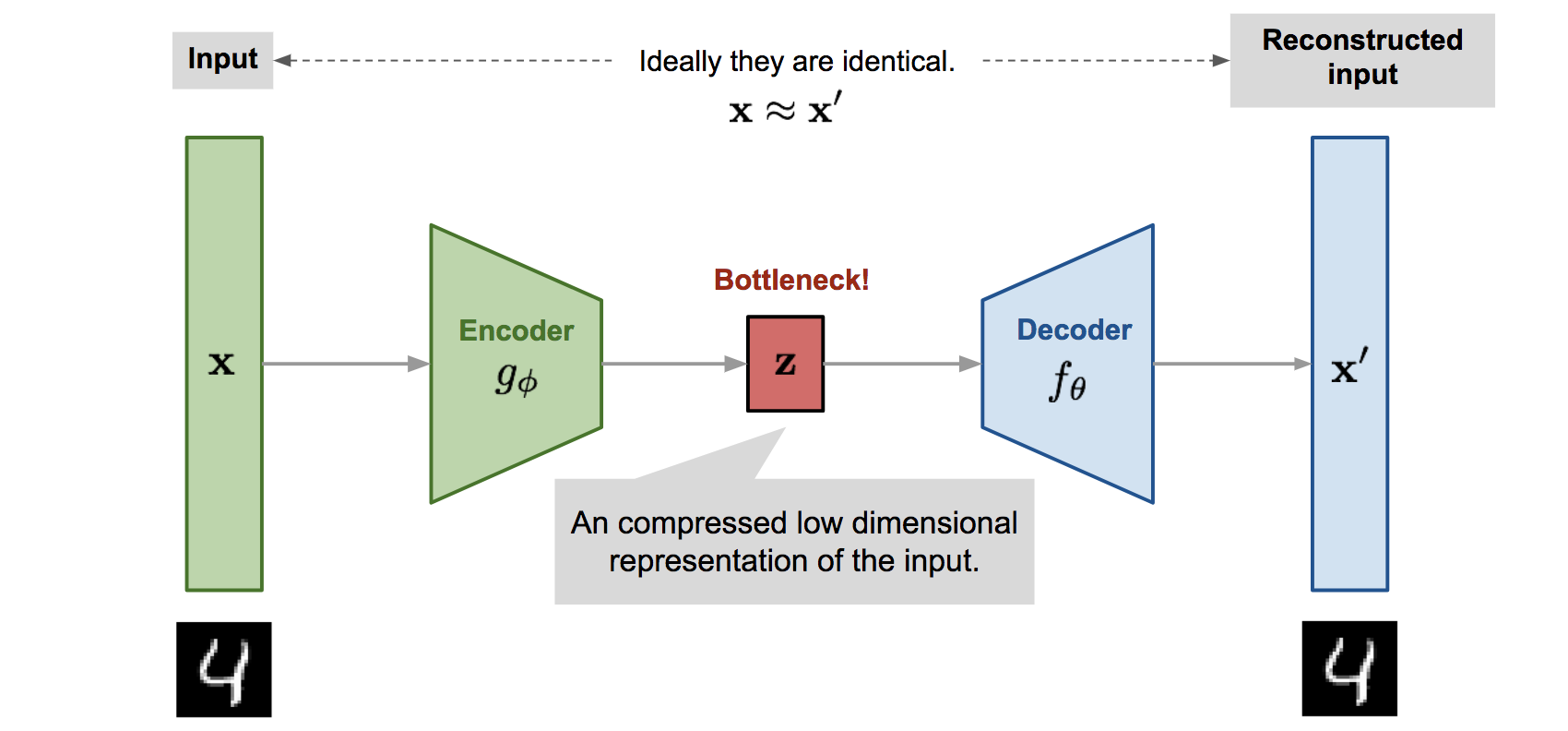
简单来说,整个神经网络构型包含编码器和解码器:
- 编码器:将 Input 输入编码成为一个隐藏向量 z
- 解码器:将隐藏向量 z 解码为和原始数据类似的信息
理解一下,隐藏向量 z 就是对输入 x 的压缩表示,编码器对应的也是一个压缩过程。而解码器对应的就是解压过程。z 编码了输入数据的核心信息,从 z 出发的解码,也是产生变化的过程。
数据流向为 x → 编码器 → z → 解码器 → x’
- x’ 为 x 的近似信息
训练过程:
- 输入 x,经过编码器,获得 z 的分布参数。
- 利用重参数化技巧采样,获得 z
- 将 z 重建为数据 x’
- 计算 ELBO 损失函数
- 反向传播,更新编码器和解码器的内部参数
核心原理
变分推断
变分推断:在用简单的分布来拟合复杂的分布,对应数学中近似思想。
在 VAE 中使用变分推断的目的是最大化对数似然 log p(x),方法是利用“变分下界(ELBO)”来近似。
ELBO 分为两项
- 第一项期望:描述从 z 构建数据 x 的能力
- 第二项是KL散度:约束编码器输出的分布 q(z|x) 接近先验分布 p(z) 的程度。
- 用此种方法可以避免过拟合的问题
ELBO 整体描述的,就是 VAE 重建数据的能力。
重参数化技巧
在编码的计算之后,获得的结果中只会输出 z 的参数,而不直接输出 z 的分布。需要用矩阵乘法乘一次才才可以获得 z 和参数之间的采样关系。
- 其中的矩阵乘法表示逐元素相乘的过程
以上这种“曲线救国”的方式,成为重参数化技巧。
如此这么做的好处是,如果直接对 z 采样,那么无法计算其梯度,后向传播算法无法更新编码器中的参数。而这样做之后,则不打破反向传播链路,使得求导过程可以继续。
KL散度 带来的效果
主要体现为正则化效果。因为 KL 散度本身就是一个约束性算法,而正则化效果也是约束性的。
从以下几个点理解 KL 散度的约束性效果:
- 强制分布对齐:编码器的输出 q(z|x) 要接近先验分布 p(z)
- 保证连续性:保持 z 中相邻点的平滑过渡
- 保证紧凑性:避免分散和空洞,使采样稳定
- 防止过拟合:避免学习过程中 z 对 x 的碎片化
- 限制 z 携带的信息量
- 避免 z 对 x 的依赖和过拟合
- 防止编码无关细节
- 生成能力的泛化
- 假定先验分布 p(z) = N(0,I) 是简单对称的,这样获得的样本的意义性更强