受限玻尔兹曼机 Restricted Boltzmann Machine
其原理受启发于物理学中的“玻尔兹曼分布”,描述例子的位置和速度的概率分布。
原理
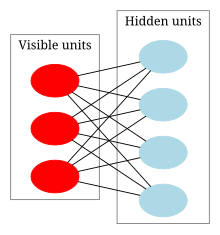
一个两层神经网络,分为可见层和隐藏层
- 可见层:控制与外部输入输出的层
- 隐藏层:控制可见层“底层逻辑”的层
算法过程
-
前向传播:从可见层计算隐藏层的激活。计算得到概率分布的参数,然后通过采样得到隐藏层的样本。
-
反向传播:从隐藏层反向计算可见层的激活。是前向传播的逆向计算方法。也是一样通过采样得到可见层的样本。
-
参数更新:利用前向传播和反向传播获得的可见层和隐藏层的激活,计算其差值,更新权重。其中正相数据代表输入数据,负相数据代表重构数据。
目标函数:能量模型
能量模型是 RBM 中衡量模型效果的指标,公式为:
- 和 代表隐藏层的偏置
- 代表可见层和隐藏层之间权重
- 和 取值为 0,1 的二值节点,通过采样获得。
目标:能量模型能量越低,表示模型的配置越合理(模型最终符合样本的概率越高)
从能量模型,可以定义一个联合概率分布:
- Z 是配分函数,但是直接计算并不可行,所以在后面用 CD 绕过计算 Z 的过程。
以上过程类比到玻尔兹曼分布就是从能量到概率的推导过程:
- P 处于某一状态的概率,E :能量,k:玻尔兹曼常数,T:温度
计算梯度并更新参数
梯度的计算方法为:
- 处理为边缘分布:该函数中的 P(v) 是已经对 P(v,h) 中的 h 做了累加求和得到
- h 被隐式处理了,因为训练数据只有 v,所以对 v 是直接处理的
处理散度(CD)
根据获得的梯度更新模型中的参数值:
- 这是通过采样的方式近似其中的负统计量
- 正相(数据期望 data 部分):降低当前数据 v 的能量
- 负相(模型期望 model 部分):提升随机生成样本的能量,抑制噪声
以上的参数更新方法,驱动参数调整,将数据对应的能量降低。