Reinforcement Learing from Human Feeback = 基于人工反馈的RL
从一个语言模型的输出语句,做上人工标记,利用原始语料和人工标记训练一个新的奖励模型,然后根据奖励模型微调原始语言模型,使得最终输出的语言模型更好的适配与人类沟通的场景。
RLHF 被广泛应用于 OpenAI 和 Anthropic 的模型微调工作中,利用该方法可以让语言模型的输出更接近于人类要求,以达到更好的输出效果。
训练的三个步骤
来自于:ChatGPT 背后的“功臣”——RLHF 技术详解
第一个步骤是训练一个原始的语言模型。这一步很简单,只需要从原始的预料,利用正常的训练过程得到初始语言模型。
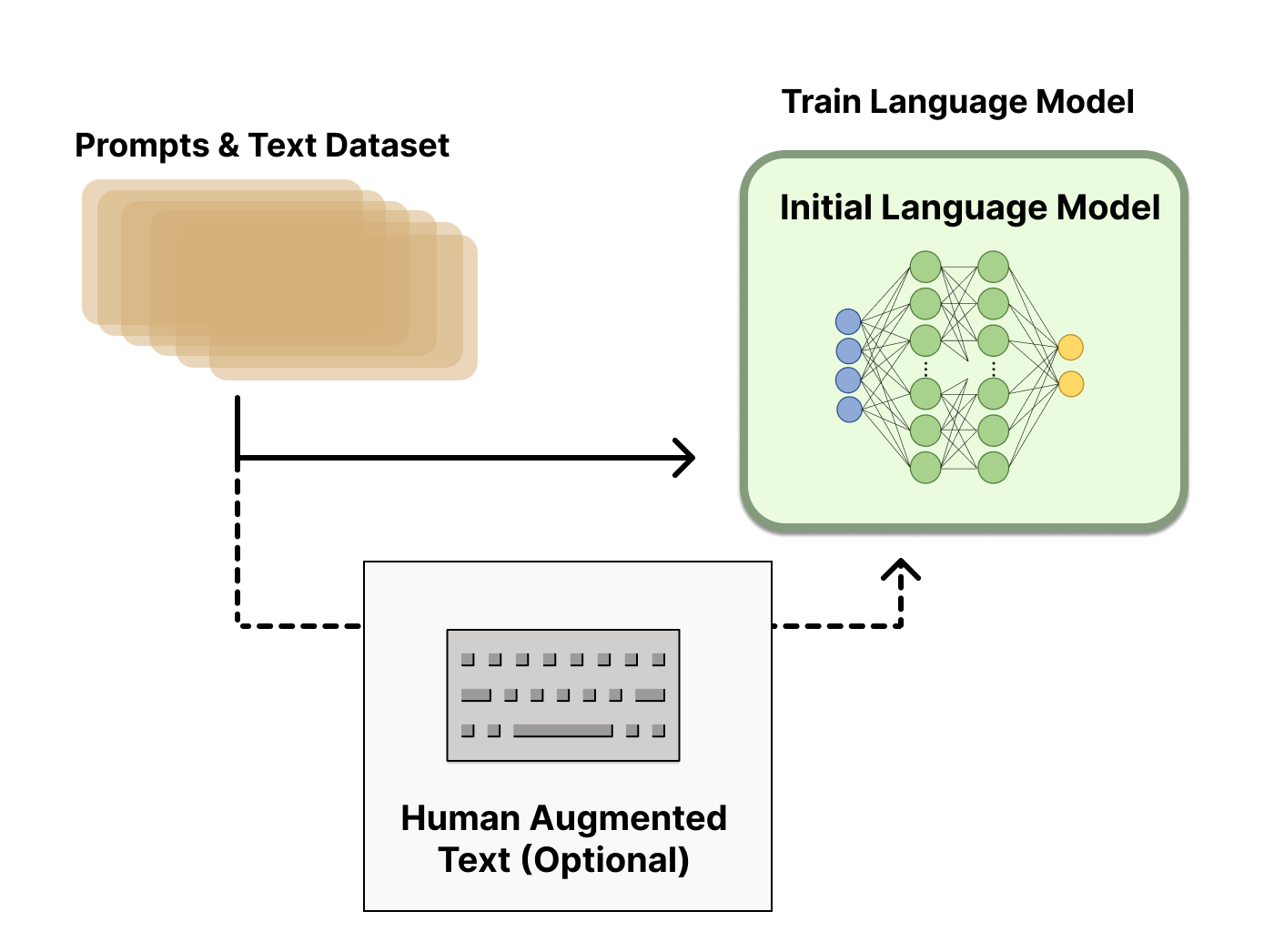
第二步,使用原始语言模型输出,经过人工对输出的标记和排序,训练一个奖励模型。
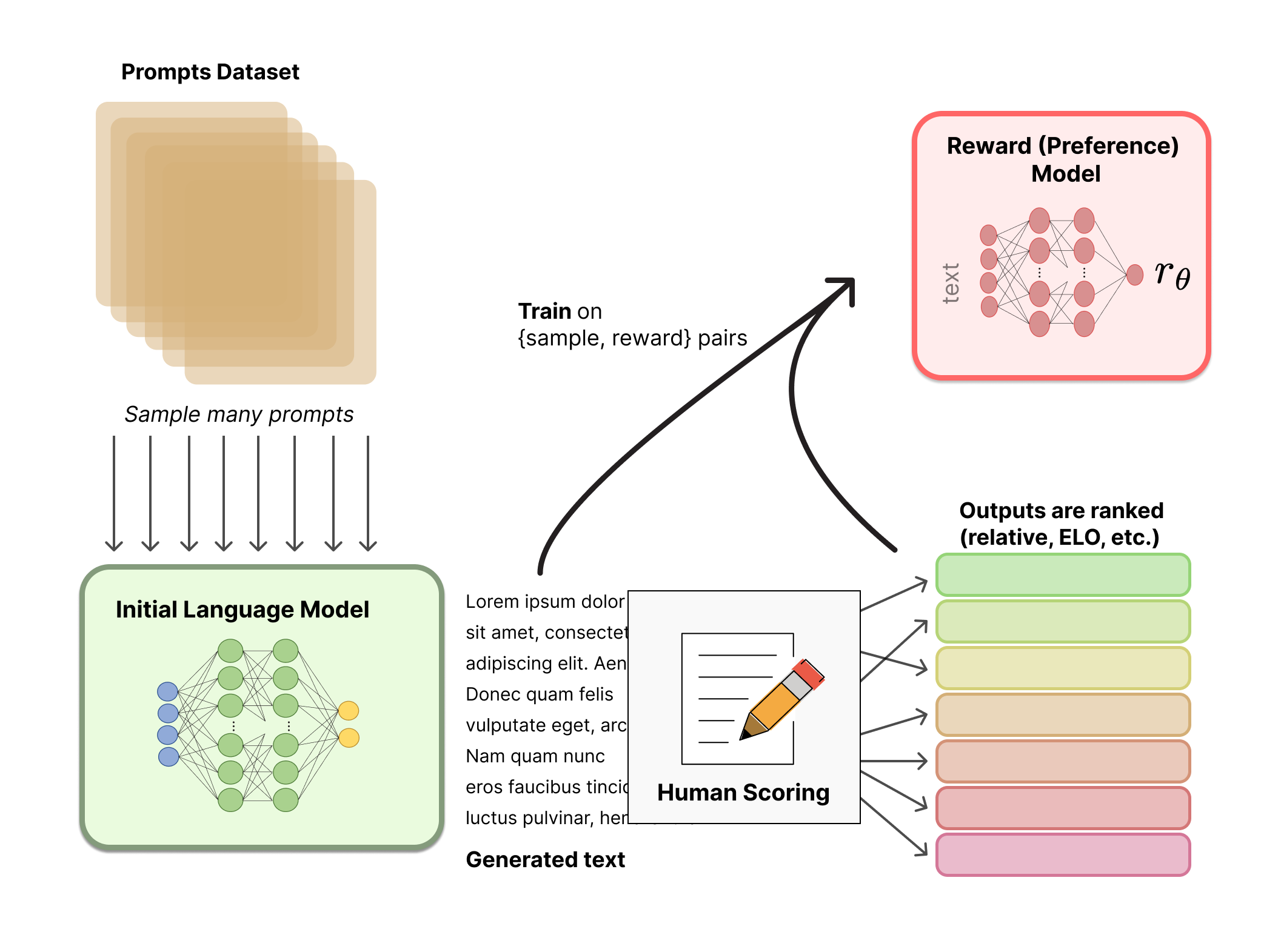
在实际操作中,对输出内容的打分排序,比较好的方式是利用 ELO算法。在挑选奖励模型时,尽量选择和原始语言模型差不多相同的结构,这样能够保证奖励模型和原始语言模型处于差不多同一个“理解水平”上,能够保证奖励模型能够理解原始语言模型的输出。
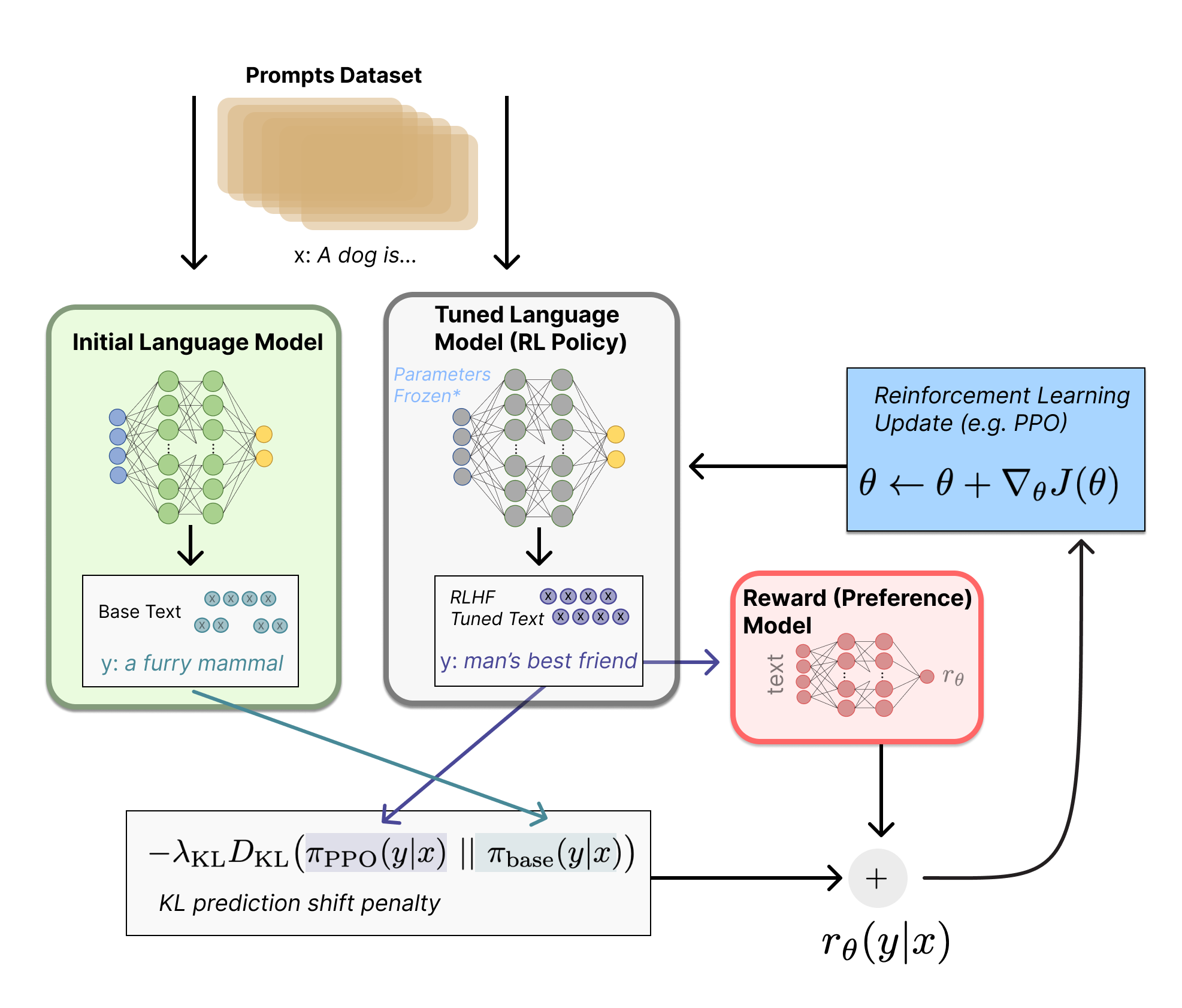
第三步,利用强化学习微调
将原始语言模型拷贝出一个新的语言模型,然后对原始语言模型与新的语言模型之间计算KL散度,之后加上奖励模型输出的奖励标量,获得最终的强化学习参数,利用 PPO 返回给拷贝出的新的语言模型做微调。
教会计算机人类世界的评判标准
从“AI的只能来自于设计者的智能水平+硬件水平+数据量水平”来看,RLHF 教会了机器学习模型“人类的喜好与评判”。
一般来讲,机器学习模型使用互联网上的语料可能是复杂而多元的,来源是不明的,可能会带有很多反人类的信息。而语言模型本身并不能判断哪些数据是好的,哪些是不好的,反而,大量“好数据”的合并也可能带来不好的输出。
RLHF 给了人类一种方式来直接评判语言模型的输出,并用一定方法直接修改模型中的参数,使得模型可以按照我们人类的意思进化、发展。
算法在大数据时代,已经不仅仅是解决一个个独立问题了,而是在数据的汪洋大海中找到人类世界的各种隐藏的或是显著的规律。这些规律可能是人类可以理解的,也可能是人类无法直接理解的。RLHF 将人类世界和计算机世界结合的更紧密了。