更多的变化:
ref:
注意力机制是一种计算机算法,其原理为:“将词汇之间关系用以数学表示”。
编码,解码和 RNN
在 attention 之前,一般使用 RNN 来编码、解码,然而 RNN 有个问题,其注意力是“线性”的,也就是当前的输出,只能对应当前的输入。
然而,attention 却做了个改进,就是将输入和输出交叉化了,意味着输出和输出不是一一对应的关系,这样的文字关系,更符合人类自然语言的语法规则。
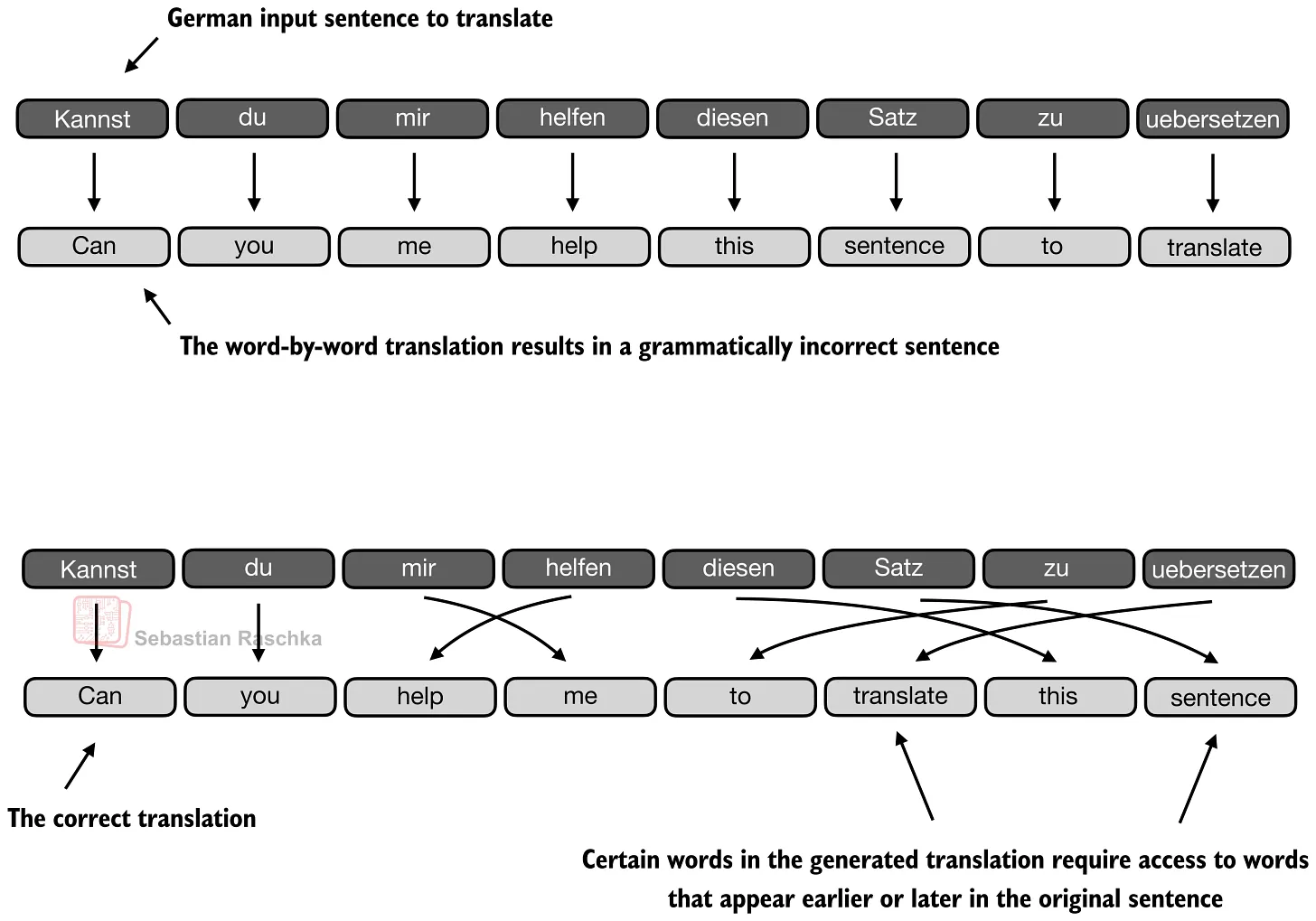
同时,attention 在输出单个单词时,允许参考前后的“上下文”,也就是参考整个语句中的词汇关系,给出当前词的输出结果。
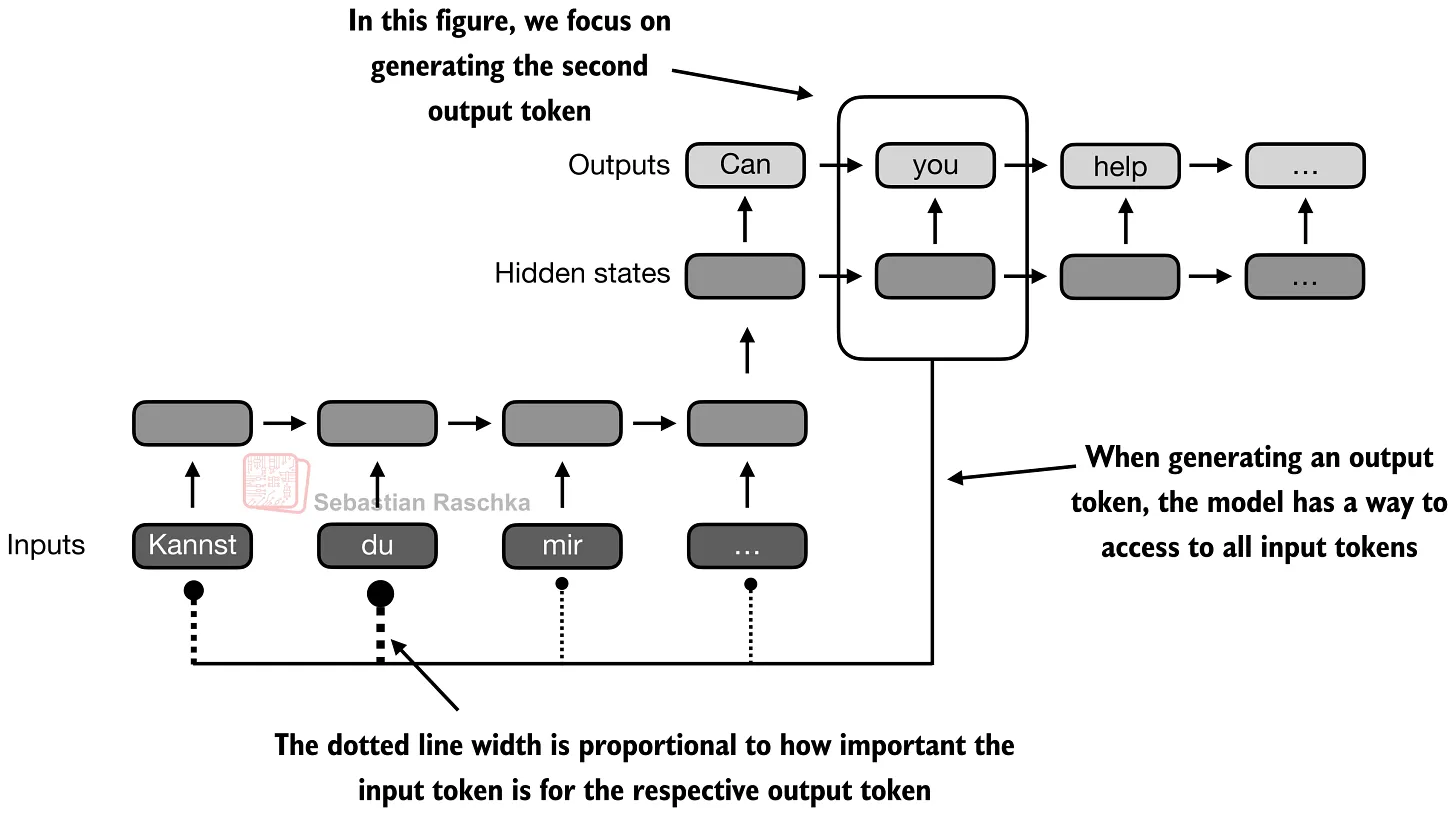
注意力矩阵
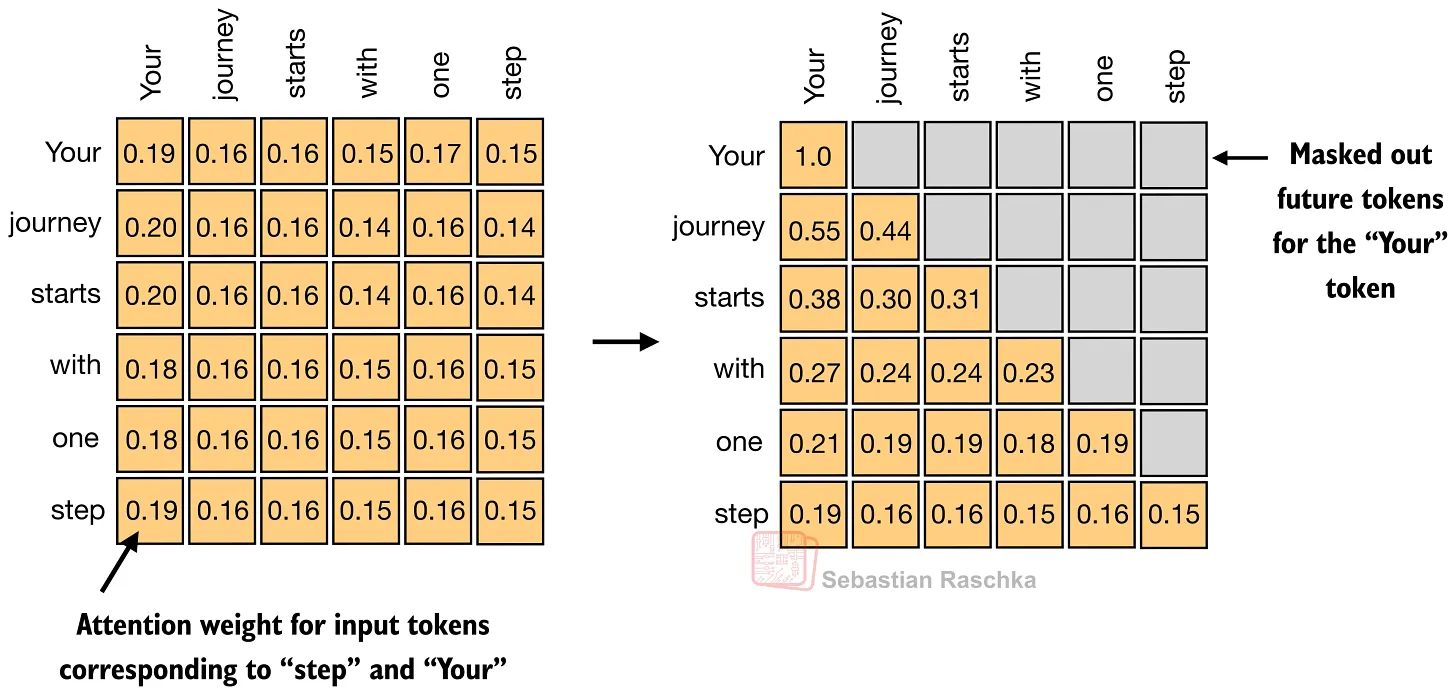
注意力矩阵是词汇之间的关系表示,也是 attention 计算的结果。可以看出矩阵内部的数字,表示的即为词汇和词汇之间的关联程度。
自注意力
自注意力,得到了一组词词之间的关联,最终得到了一个“注意力矩阵”。
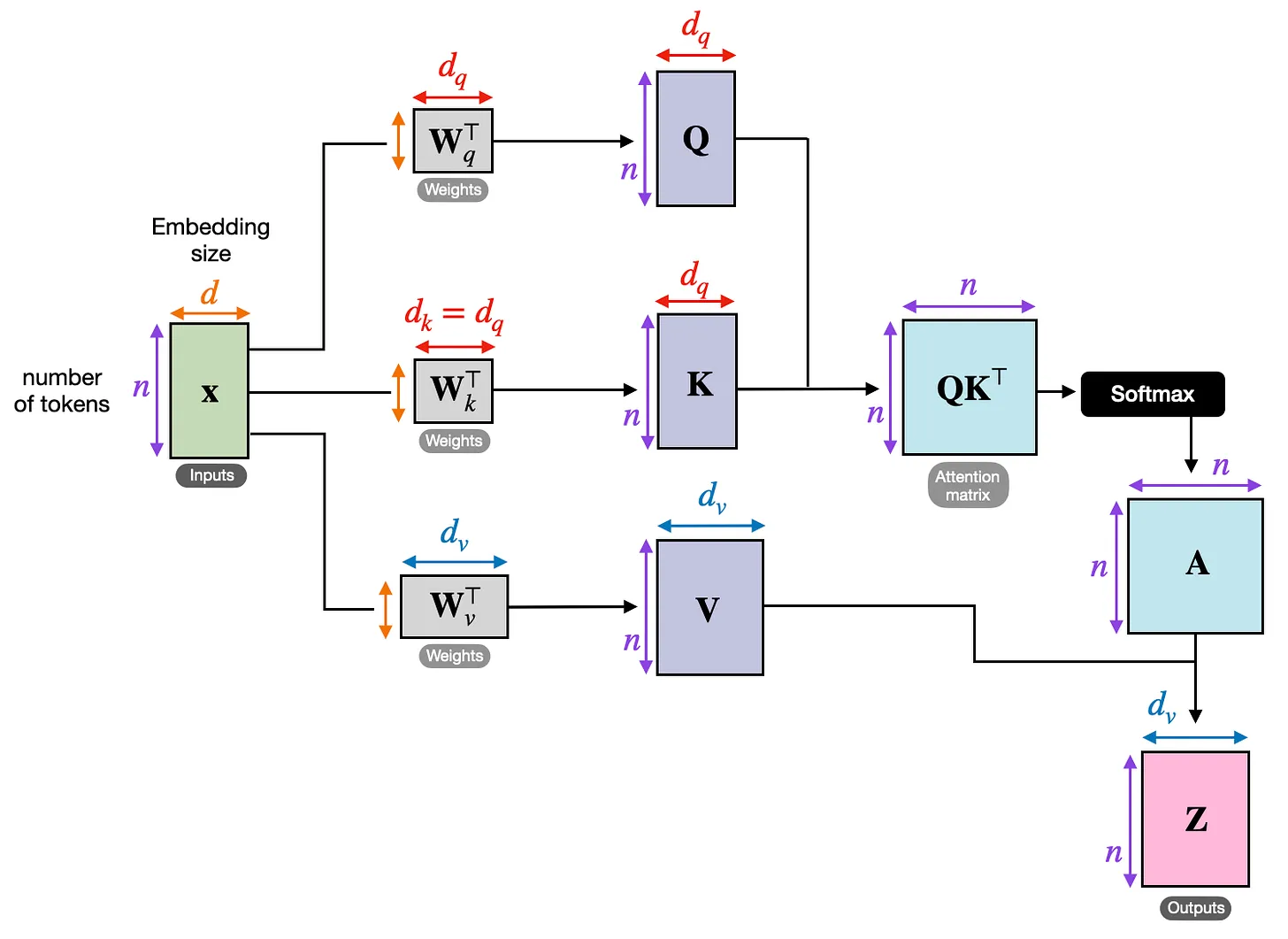
以下是一个词,通过计算得到的上下文向量。可以注意到,单个词作为 q 进入,而 K 和 V 的计算则是需要“整句话”X 的整体输入的。
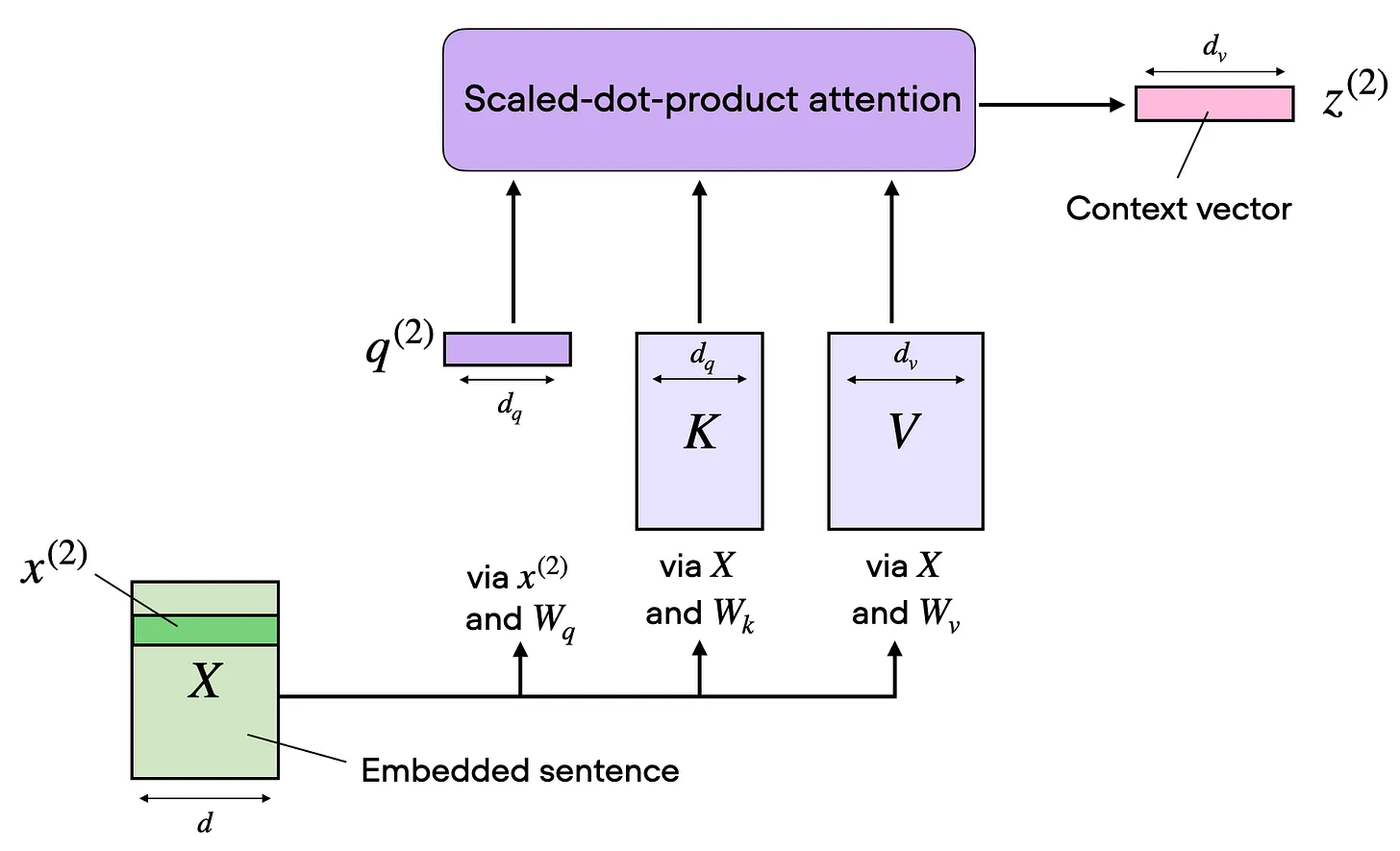
另一个来自 coursera 的笔记
自注意力
注意力机制衡量是文本之间关系的机制。也是 Transformer 模型
单个注意力也叫“自注意力”,用于表示在一个文本序列中各个概念之间的关联。
例如“我的家在北京公主坟”这句话,经过中文分词,可以获得“我,的,家,在,北京,公主坟”这么几个词元。单个的自注意力可以通过大量的训练集,找到不同词元之间的关系大小。例如“家”和“北京”,“公主坟”都属于表示“地点”的概念,那么在“地点”这个主题下,“家”、“北京”和“公主坟”这三个词获得的注意力值会更高,与“的,在”这些词汇之间的值则更小。
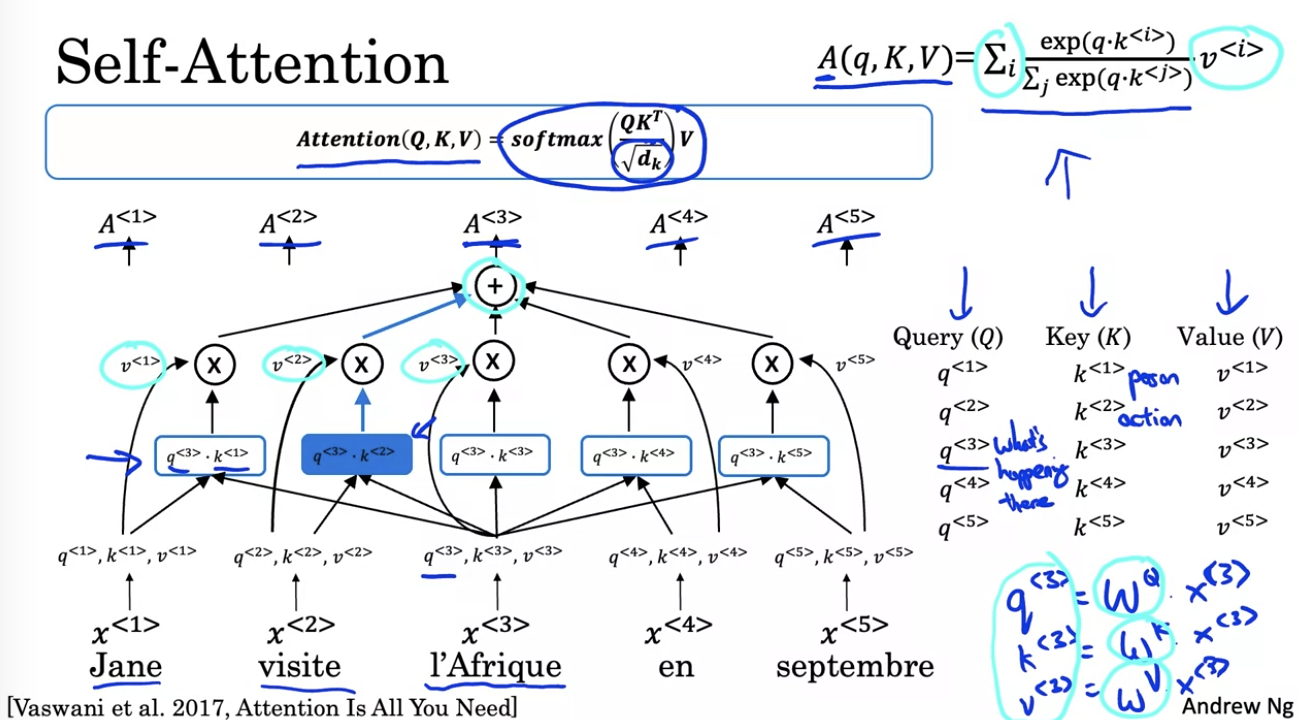
对于句子中的单个词汇,我们用三个值来表示 Q,K,V。这三个值可以通过线性变换计算。
直观理解:
- Q 表示一个“问题”,我的理解是一个“主题”,也叫一个“头”。
- K 表示单词的一个含义或者一个特征。
- V 表示单词在这个含义上的关联程度。
MHA 多头注意力
而很多个“自注意力”集合在一起就变成了“多头注意力”。通俗地讲,就是可以在一句话中同时提炼多个主题(就是“头”的概念),然后同时计算。
例如“我的家在北京公主坟“就可以同时计算好几个相关的头,可以是“问题”也可以是“地点”。每个不同的主题就会提取不同的词元。然后计算其相关性。
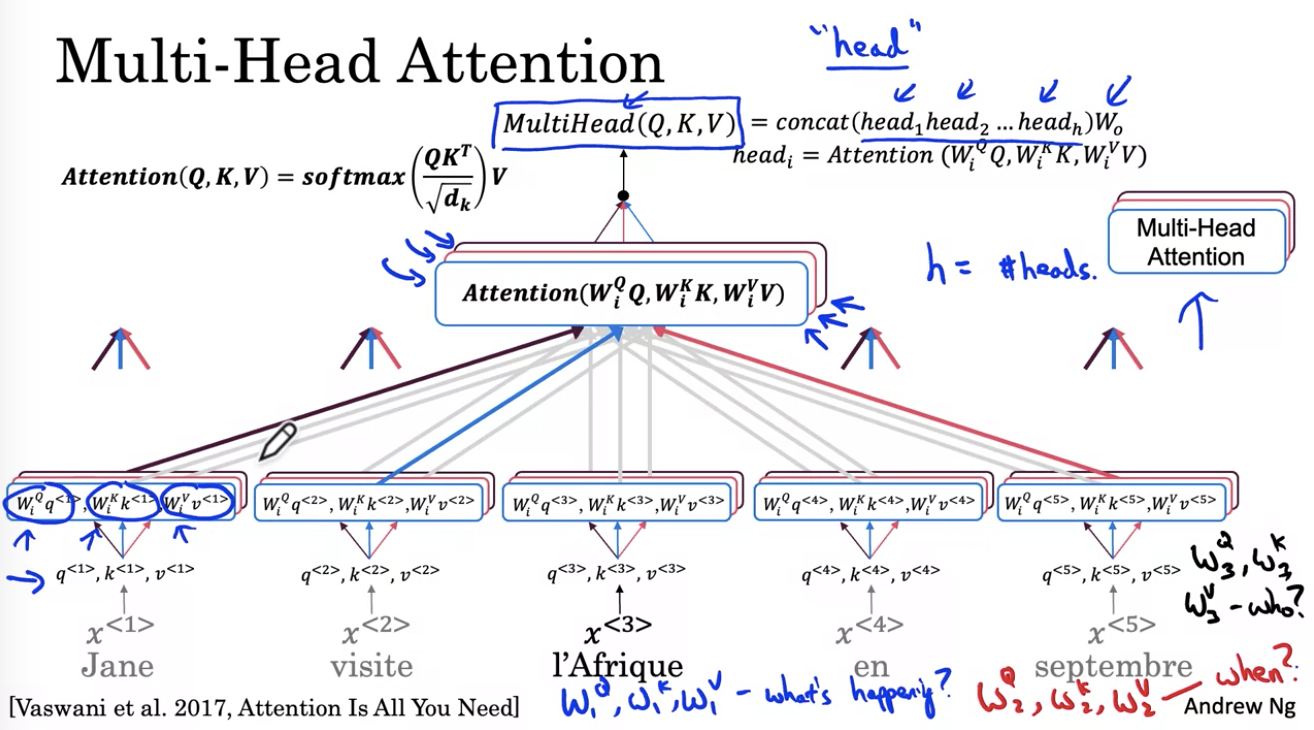
上图是一个文本理解任务的例子。其中包含了两个头,蓝色表示“发生了什么事?”,红色表示“什么时候发生的?”。
多个头在注意力网络中可以同时并行地计算。
理解的本质?
类比到我们人类的理解能力。我们所谓的“理解”其实也是在我们面前发生的许许多多的事情中找到其规律。当我们的大脑能够对概念之间建立连接之后,才让我们产生了新的理解。
例如当我们提起“大象”的时候,我们就会想起许多概念,例如“哺乳动物”,“很大”,“皮肤很粗糙”。除了概念之外,我们还会想起大象的基本形状,长长的鼻子,如果去过动物园见过或者摸过大象,我们还能感受到它粗糙的皮肤,想起它像吹喇叭一样的叫声和缓慢的动作。
正是我们这些脑海里的“印象”组成了我们对于“大象”的理解。
而注意力机制就提供了一种量化的算法,把“理解”这件事情在文本处理领域 ,用数值量化了。