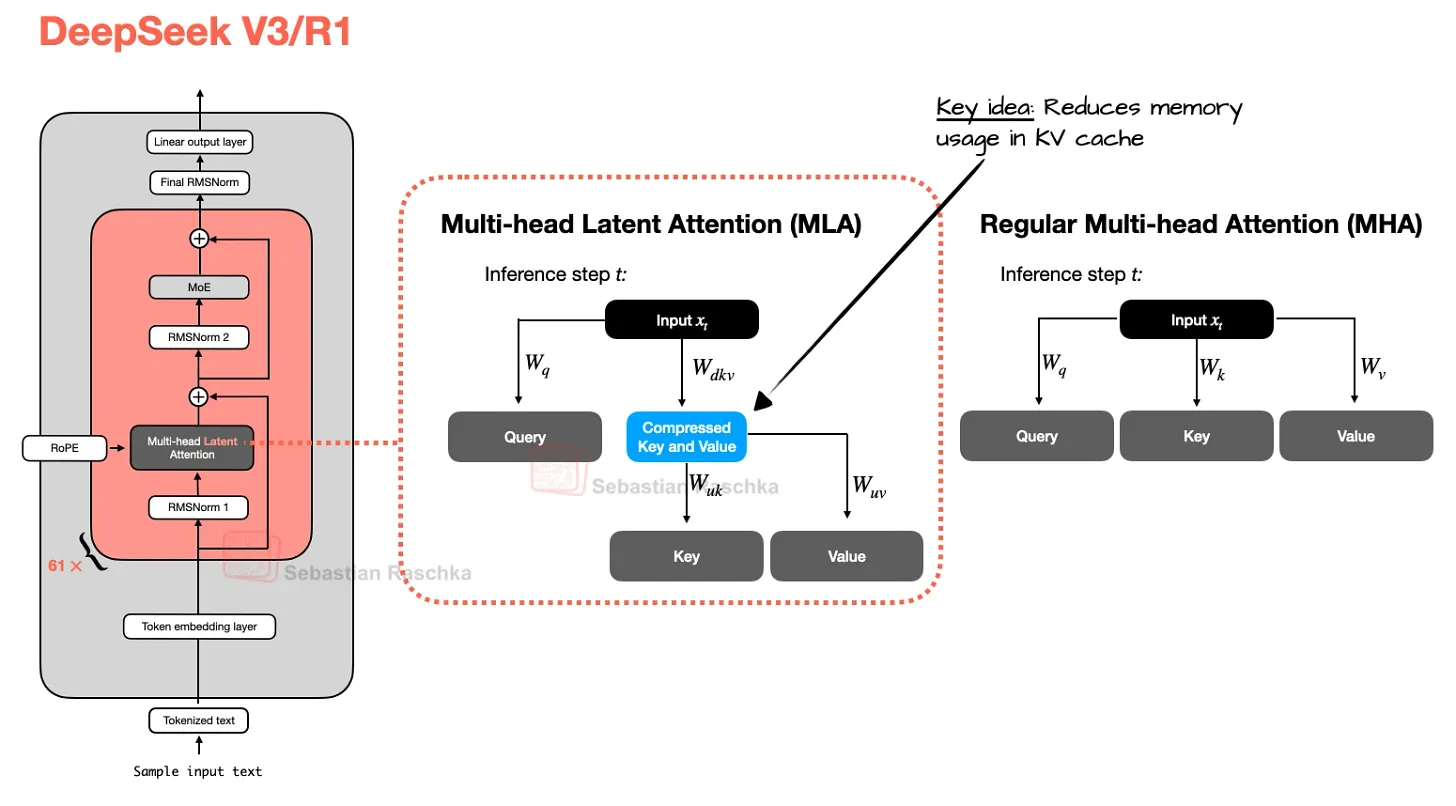
MLA,Multi-Head Latent Attention ref: A Visual Guide to Attention Variants in Modern LLMs 多头潜在注意力,也是多头注意力的优化形式,是 DeepSeek 的主要模式,用以进一步压缩 KV 的尺寸。 这种方式虽然提升了模型性能,但是实现和服务的方式会更复杂一些。