Mixture of Experts,混合专家模型。是 LLM 的一种优化手段。
ref:
基础的做法是:将 LLM 中的前馈网络层(FeedForward)模块,使用一个带 Router 路由的节点做分发。
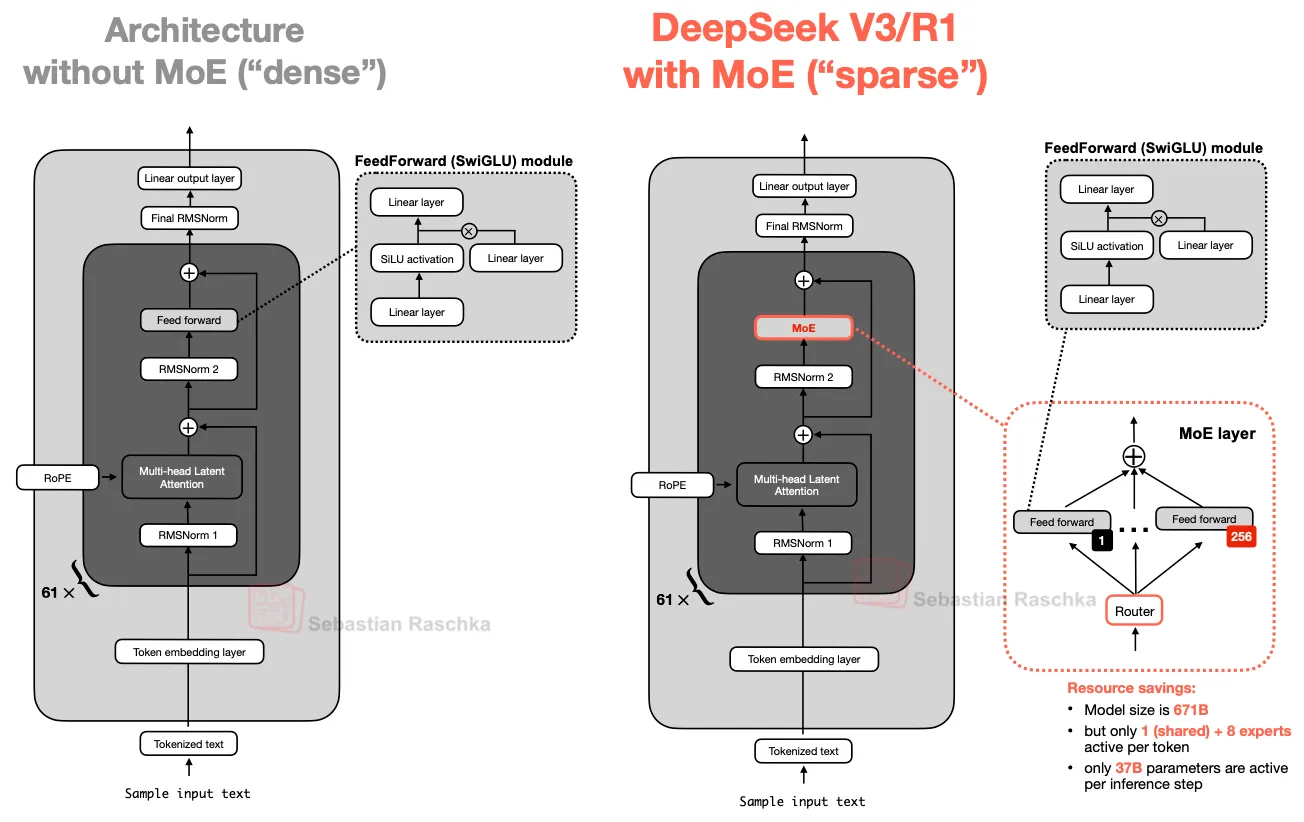
Router 是一个分发器,将输入的 token 分发到不同的前馈网络进行计算。
对于输入的每一个 Token,Router 都会根据情况进行一次分发。
前馈网络一般在 LLM 中包含着大量参数,通过 Router 的分发,可以让模型拥有巨量参数的情况下,进行效率上的优化:每次仅激活一部分参数,提高计算效率。