KV-Cache:对多头注意力的缓存和存储。
Transformer 架构中,使用注意力进行 token 的预测和计算。
KV-Cache 是一个避免重复计算而提升 llm 性能的机制。
ref:
Motivation
在注意力计算的过程中,对每一个 token ,需要计算其 Q 然后和之前的 token 计算 K V ,然后才能得出下一个 token 的概率分布,最终输出 token。
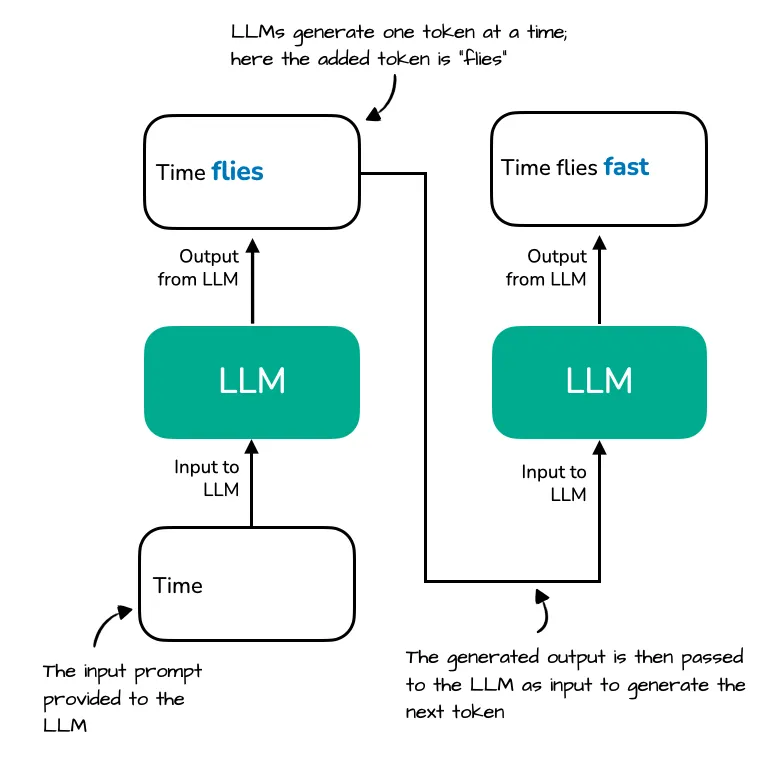
然而,后续计算的 Q K V 中的 K V 之前都已经计算过了,如果不存在 KV-Cache 的话,这些 K V 都要被重新计算,计算开销十分大。
细节
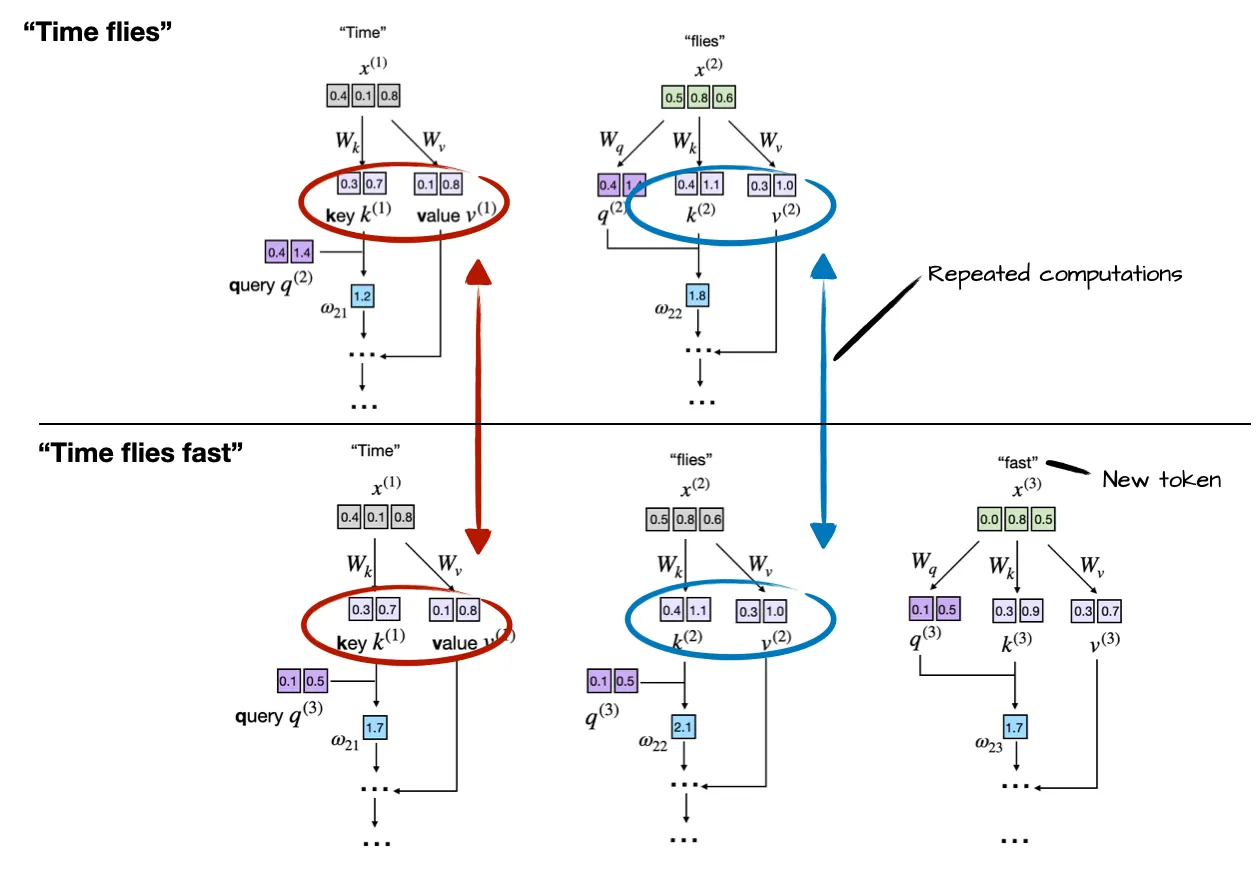
在计算 Time flies fast 的下一个 token 时,需要计算 Time flies fast 所对应的所有 K 和 V。
并且在后续的计算中,所有之前计算过的 K 和 V 都要重复获取。
而 KV-Cache,就是将已经计算过的 K 与 V 全部保存起来,在后续的计算中不会被重复计算。
注意点
KV-Cache 名字虽然如此,但是这里的 K 和 V 并非传统缓存意义上的 K 和 V。传统缓存系统例如 redis 经常使用 KV-Store 这样的名字,表示是一个键值对的存储,而这里的 KV 实际上指的是 Transformer 中使用的 KV 参数