Multimodal LLM,多模态 LLM,能够处理“多媒体”模态的语言模型。
ref:
如何将图片信息输入到 LLM 中
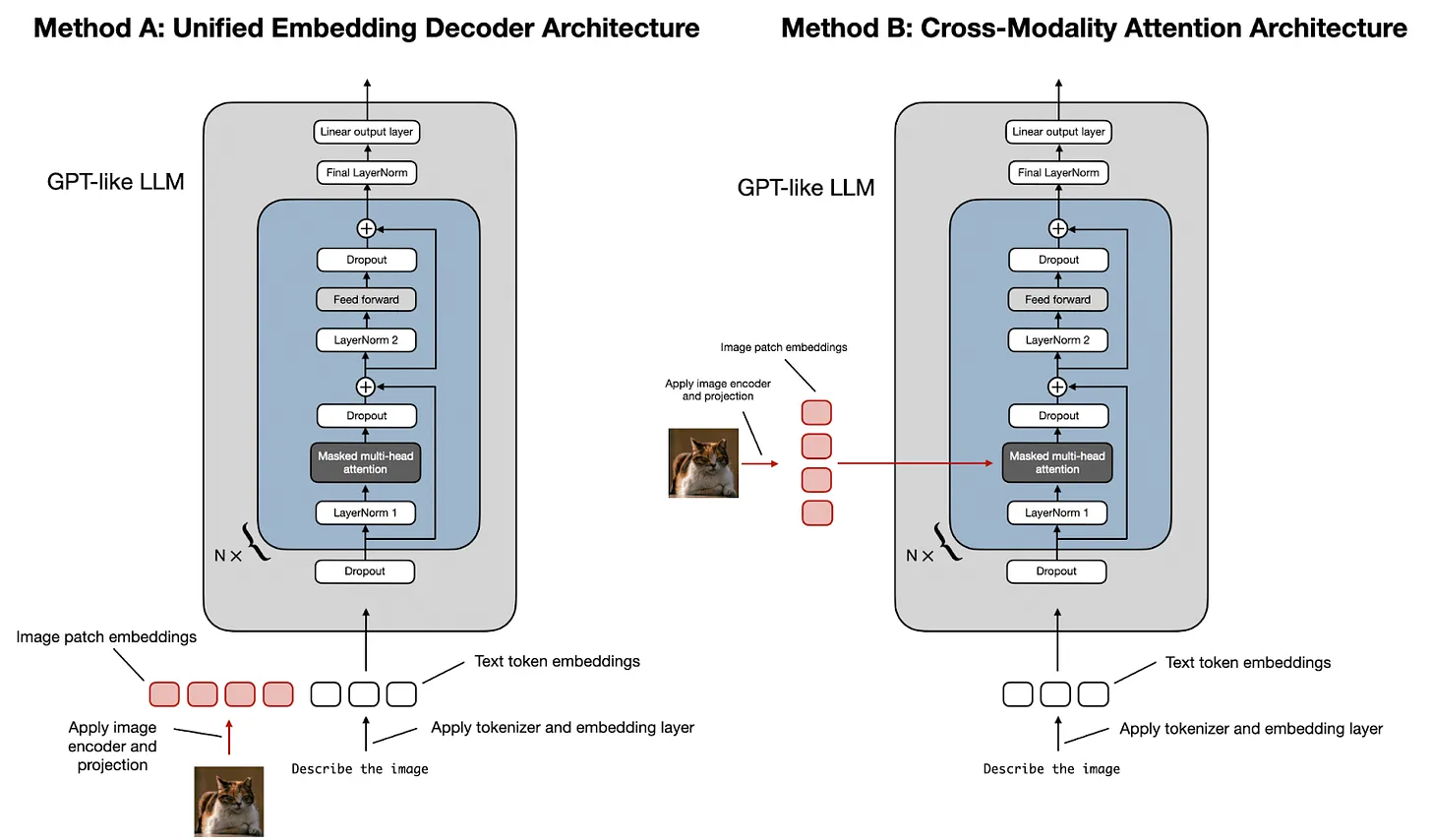
以上是多模态 LLM 的示意图。以上的 LLM 的基本结构是 Transformer 结构。
以图片为例,一般会使用一个模型,将图片处理为和文字一样维度的 Token,然后输入给 Transformer Decoder。
有两种方式:
- Unified Embedding Decoder Architecture 统一嵌入解码器架构。就是将图片处理成和文字一样的 Token,和文字 Token 一起混同输入到 Transformer 中。
- Cross-Modality Attention Architecture 跨模态的注意结构。图片的 Token 直接输入到注意力层,类似于 Transformer 架构中 Encoder 将信息输出给 Decoder 的过程。
两种方式各自有 TradeOff,统一嵌入编码器的方式不需要修改 LLM 结构,但是性能较差,而跨模态注意力结构性能较好,但是因为需要修改 LLM 结构,所以工程上较为复杂。
图片信息处理
将图片处理成 Token 的方式,也就是“编码”图片,这个编码器,一般称为 ViT (pretrained vision transformer)
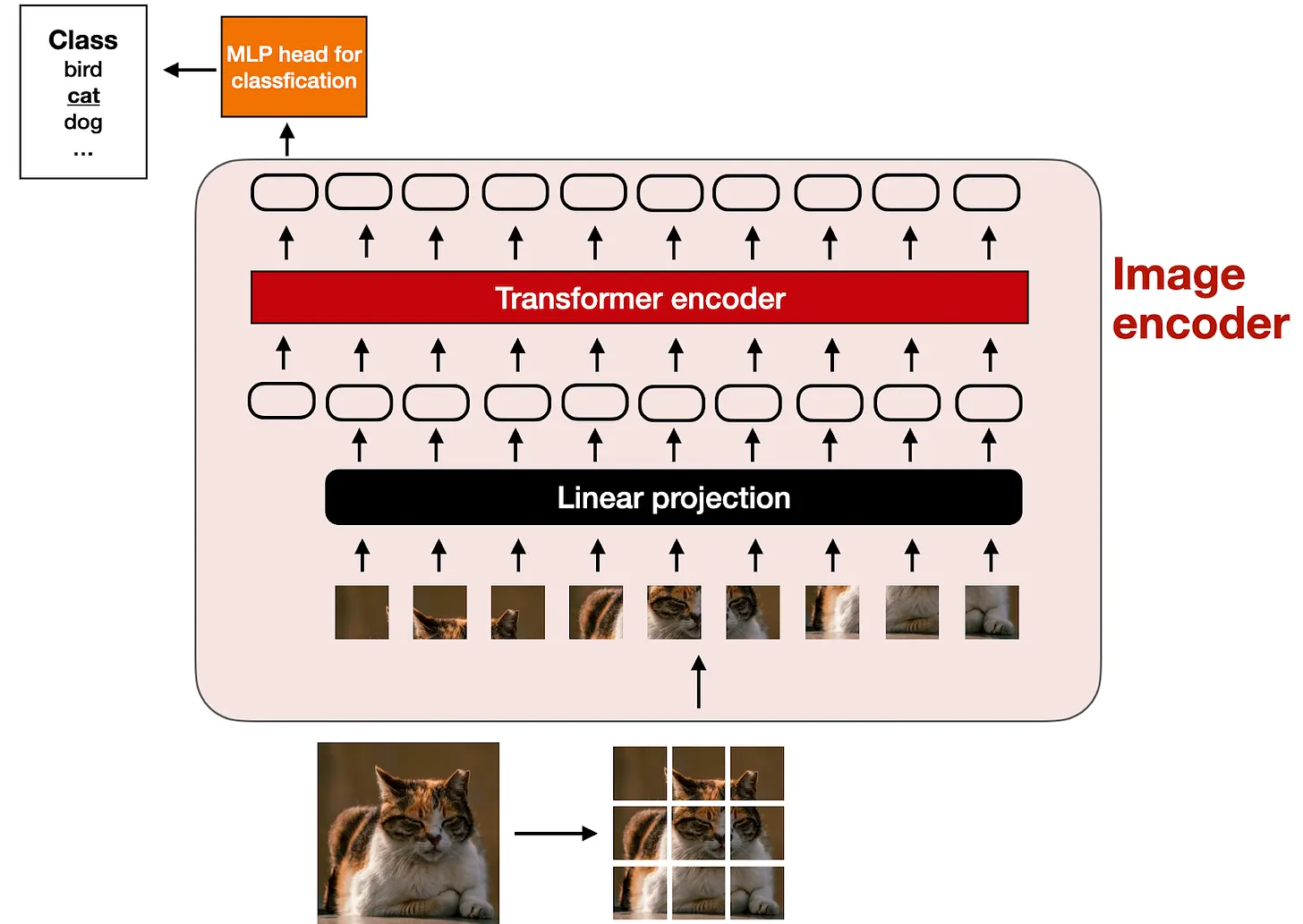
图示为一个 image 的 classifier 任务,但是实际上,在图片处理的过程中,我们仅将图片处理到 encoder 之后的输出即可。