Apache 规范的,存储列表数据的文件组织格式。
ref:
主要应用于大规模数据存储和处理的场景,也用于机器学习场景。
基本结构
和 SQL 等关系型数据库不同,Parquet 按列组织数据。以此达到数据高效读写,检索的功能。这点在机器学习中格外重要。
数据按照以下方式组织:
4-byte magic number "PAR1"
<Column 1 Chunk 1>
<Column 2 Chunk 1>
...
<Column N Chunk 1>
<Column 1 Chunk 2>
<Column 2 Chunk 2>
...
<Column N Chunk 2>
...
<Column 1 Chunk M>
<Column 2 Chunk M>
...
<Column N Chunk M>
File Metadata
4-byte length in bytes of file metadata (little endian)
4-byte magic number "PAR1"
- 文件开头和结尾的标识位为“PAR1”
- 文件中间 Column 被分段存储,每个 Chunk 组织成一个 Row Group,并且 Row Group 带有 metadata 可供查询时检索使用。
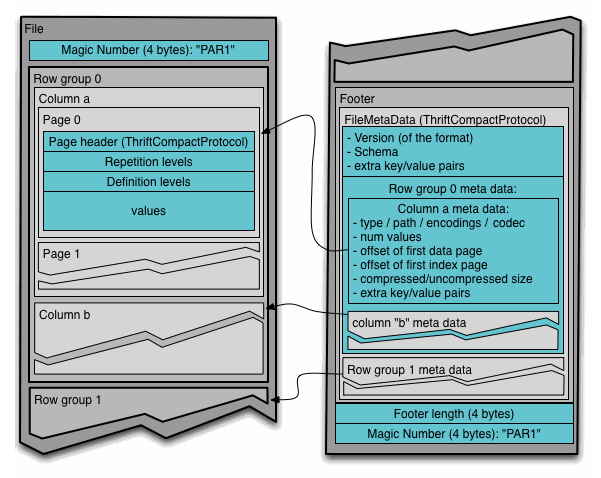
- File 表示文件
- Row Group 表示行数据组
- Column 表示列数据(每一个 Row Group 中包含一个列数据的组)
- Page 表示数据页
Row Group 的引入,是为了优化两类数据查询性能:
- 投影下推:类比到 SQL 的 Select 查询语句。表示每次查询得出的数据,仅仅是原始数据的一部分,也就是一个“投影”
- 谓词下推:类比到 SQL 的 Where 条件语句。表示查询的谓词条件关系。
关于谓词下推:查询时,可以根据 Row Group 的 meta 中的数据,确定当前数据分片中是否存在这个数据,如果确定是不存在的,则可以直接跳过,提升查询的效率。
Metadata
Metadata 是数据的元数据,可以看作是数据的索引
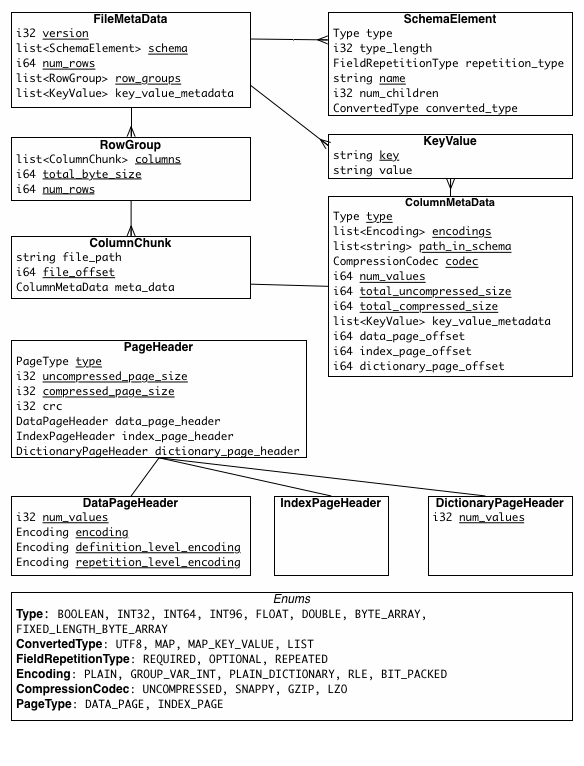
- File Meta ,文件的元数据,包含了对 RowGroup 和 ColumnChunk 的数据索引。还有 Column 的数据信息与数据指针。
- PageHeader,包含了对数据页的元数据。