Random Forest
基于决策树的学习模型,于 2001 年由 Leo Breiman 提出。通过构建多个决策树并结合预测结果。
算法过程
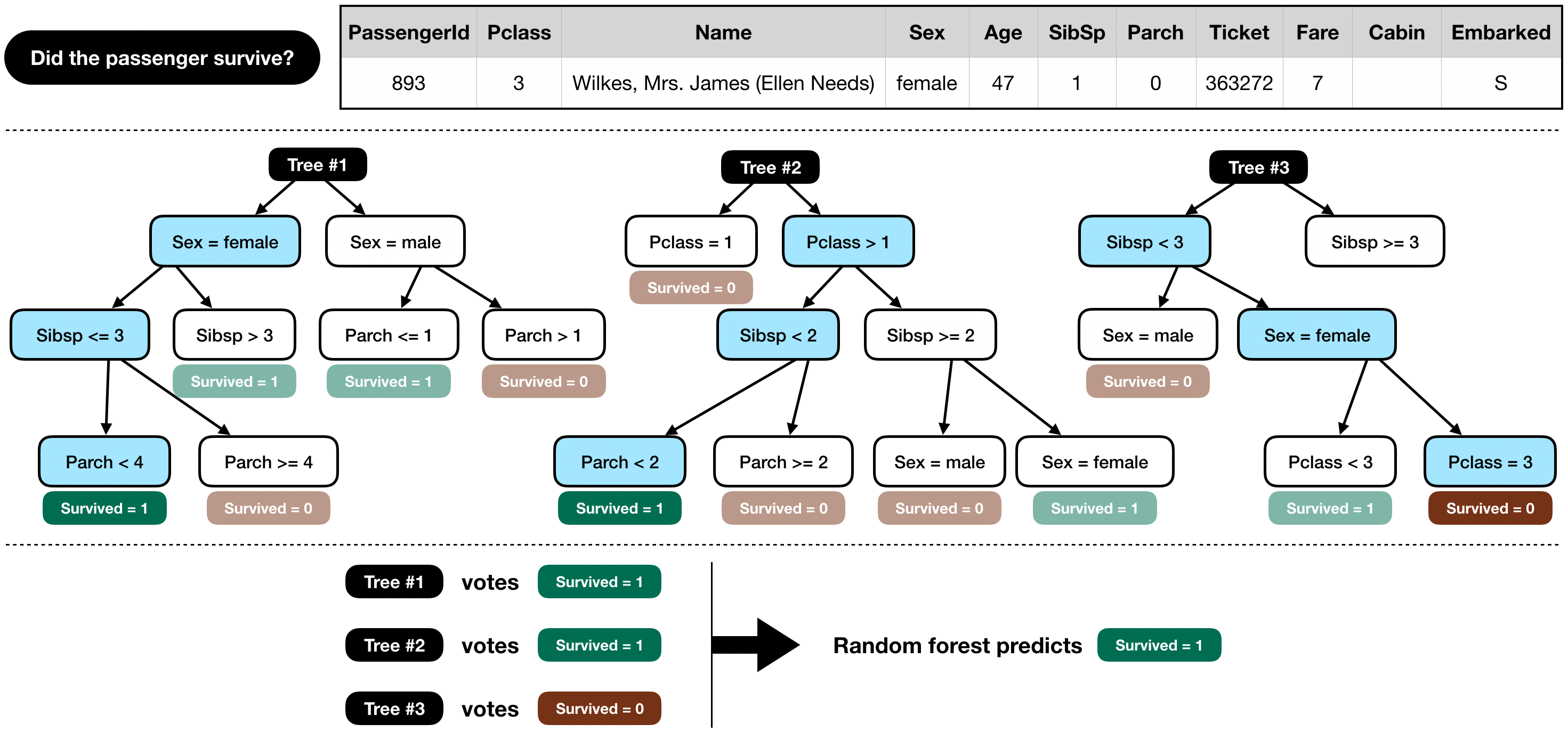
- Bootstrap 抽样:有放回地随机抽取样本,形成数据子集
- 特征随机选择:子集训练决策树时,仅选择一部分特征做数据划分
- 构建决策树:可以参考决策树的构建过程,参考熵增算法
- 结果集成:多个决策树形成决策树的森林,对每个输入数据,不同的决策树投票取得最终的结果。
优缺点
优点
缺点
- 计算资源消耗大
- 可解释性差
- 样本不平衡
思考
随机森林是典型的“多合一式”算法优化。将多个计算过程合并在一起以降低输出结果的随机性,也就是优点中的降低“方差”。