串行与并行的辩证关系
在计算机系统中,并行处理能显著提升性能,但某些关键步骤仍必须采用串行方式。优化这两种处理模式的方法各不相同:
- 串行优化:采用流水线技术,计算时间取决于最慢的瓶颈步骤
- 并行优化:通过纵向分治将任务划分为K份,理论执行时间可缩短至1/K
8.1 指令流水线:物理并行的串行逻辑
CPU指令执行三阶段
- 取指(Fetch):从存储单元获取指令
- 译码(Decode):解析指令含义
- 执行(Execute):
- 读取操作:内存→寄存器数据传输
- 写回操作:寄存器→内存数据传输
流水线技术优势
由于CPU使用不同硬件单元处理不同阶段,流水线技术能让多条指令重叠执行,大幅提升吞吐量。例如当第一条指令进入执行阶段时,第二条指令可同时进行译码,第三条指令开始取指。
思考题8.1:分支指令对流水线的影响
条件分支(if)会打断指令预取,导致流水线清空或预测错误,可能降低效率30%-50%。现代CPU采用分支预测等技术缓解此问题。
8.2 摩尔定律的演进历程
- 2000年前:通过提高时钟频率和增加处理器位数(4位→8位→16位→32位→64位)提升性能
- 2000-2016:转向多核处理器和GPU,采用并行架构处理数据
- 2016年后:追求能效比,发展ASIC等专用芯片
8.3 分布式系统典范:GFS与MapReduce
Google文件系统(GFS)设计
PageRank处理大量网页的方法,将网页合并为大文件,以 64M 分块保存。
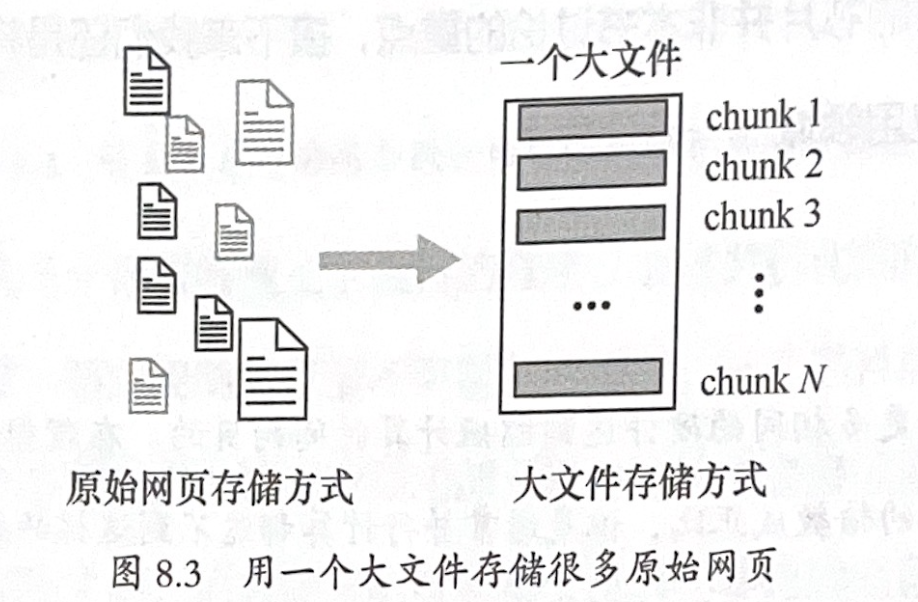
在大文件中,建立索引查找文件。
大文件的好处和劣势:
- 好处:串行读写更快,适合流水线作业
- 坏处:随机查找困难;无法用新内容覆盖旧内容;对使用者不方便,因为使用者不知道文件的具体存储位置。
设计目标:优化海量数据存储而非随机访问
架构特点:
- 主从式结构:主服务器管理元数据,块服务器存储实际数据
- 64MB大分块存储:提升顺序读写效率
- 三重备份策略:不同机架的块服务器存储副本
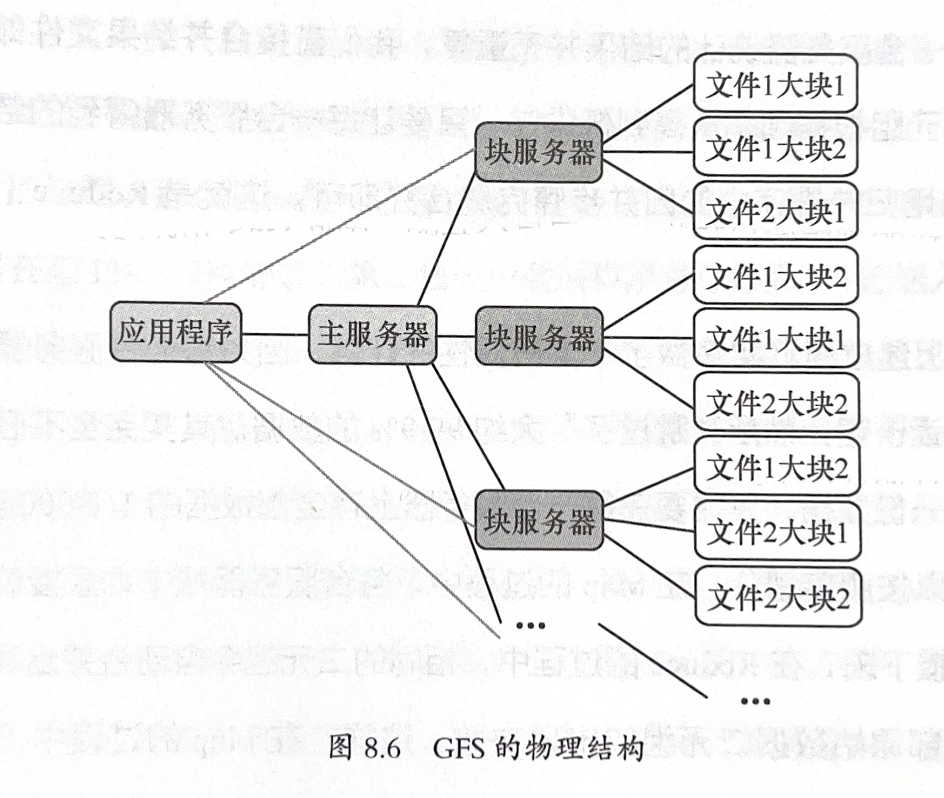
优势:
- 主服务器和数据块之间加入块服务器,这样主服务就不会成为瓶颈
- 能够使用大量廉价的服务器
备份的处理:备份放在不同块服务器上,增加可靠性和安全性,增加读写带宽。
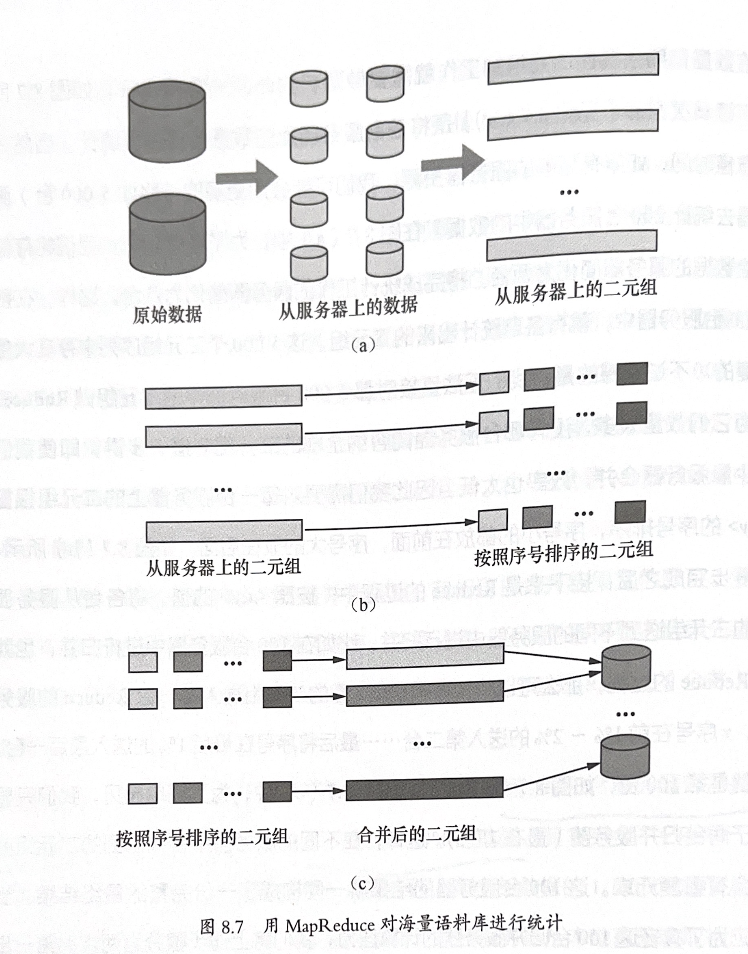
MapReduce并行计算框架的一个例子
基础版本
- Map阶段:每台服务器存储所有数据,但只统计自己对应部分的二元组。
- Reduce阶段:将所有服务器上的二元组统计合并。
优化版本
- Map优化:每台服务器仅处理0.1%数据
- Reduce优化:两阶段归并排序
- 按key范围分片归并
- 最终全局归并
大规模分布式实现(采用两次Map一次Reduce模式)
动机:如果数据量特别大,一个服务器无法完全处理所有的二元组数据。那么就需要分布式处理了。
数据分布:100台存储服务器+2000台计算服务器
执行流程:
- a 复制和统计:每个从服务器向原始服务器中拿取属于自己那部分的数据,然后统计二元组
- b 排序:从服务器上的二元组按照 从小到大排序
- c 归并:按照序号两次归并
- 第一次:在多个服务器上,每个服务器做一部分 x 序号的归并
- 第二次:最终得到完整结果的归并,使用的服务器更少
计算复杂度分析
- 时间复杂度
- 步骤 a 复制和传输:瓶颈在读数据的服务器上。读 D/100 的数据。因为读、传输和写是串行可用流水线优化。这三部分的时间定义为网络传输时间
- 步骤 a 统计二元组:基本上是复制一遍数据的时间
- 步骤 b 排序二元组:也相当于复制一遍的时间
- 步骤 c 归并:时间主要在网络传输,第一次归并为 第二次归并因为没有重复直接复制,为
- 总结:
- 空间复杂度
- 不会超过原始数据,为
总结: map 容易并行处理,拆分即可,reduce 视情况而定
思考题8.3:分布式系统实践
Q1:备份校验与修复
- 100TB的数据假设存储在 100 台服务器,备份 3 则数据应有 300 TB
- 所有的数据是关联的,每个数据有一个序号,在读取一个文件的时候可以找到另外两个备份所在的位置
- 检查数据完整性的服务器假设有1000台。每台服务器负责检查 0.1TB 的数据,总共要处理 0.3 TB 的数据
- map:将 100 TB 分为 1000 份,每一份拷贝到一台服务器上,并把备份也拷贝过来。然后做完整性检查,将检查好的数据写回硬盘,写回硬盘的数据为 0.1T
- reduce:将所有的数据合并,即拷贝一遍即可
Q2:典型MapReduce问题 如倒排索引构建、网页排名计算等需要先分布式处理再合并结果的场景都适合采用MapReduce框架。