引子:统计二进制数中1的数量
统计32位或64位二进制数中1的数量有两种经典方法:
-
查表法:预先存储每个字节(8位)中1的个数,然后通过查表快速统计。这是典型的空间换时间策略,时间复杂度为O(|B|/k),其中k为分块大小。但k值不能过大,否则会超出CPU缓存限制。
-
位运算法:使用 x&(x-1) 技巧:
count = 0;
while(x != 0) {
count++;
x = x & (x-1);
}7.1 顺序与随机访问
访问模式的特点
- 顺序访问:从头到尾线性访问,适合批量读写
- 随机访问:任意位置直接访问,灵活性高
存储设备特性决定了访问效率:随机存储器容量有限,外部存储器容量大但主要支持顺序访问。
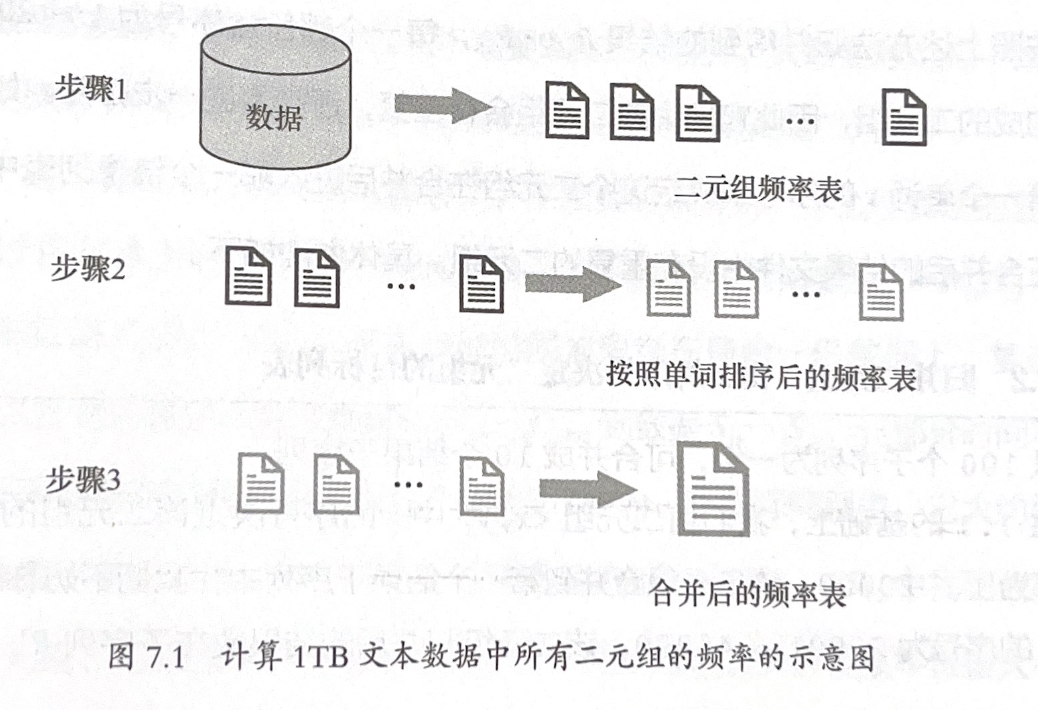
例题7.2:高频单词二元组问题
在1TB数据中找出频率最高的100万个单词二元组。
不可行方案:
可行的近似方法:
- 随机抽样:抽样 1GB 数据,然后统计保留频率最高的 1000 万个二元组,然后假定 1TB 数据中最高频的 100 万个二元组在 1000万二元组之中,其他就直接忽略
- 限定范围:统计词频,因为二元组的数量不会超过词频,排除低频词汇以后,再统计包含这些词语的二元组的数量,这样可以大大减少计算量
可行的分治法MapReduce:
Map阶段:数据分片,统计各片段的二元组频率
Reduce阶段:
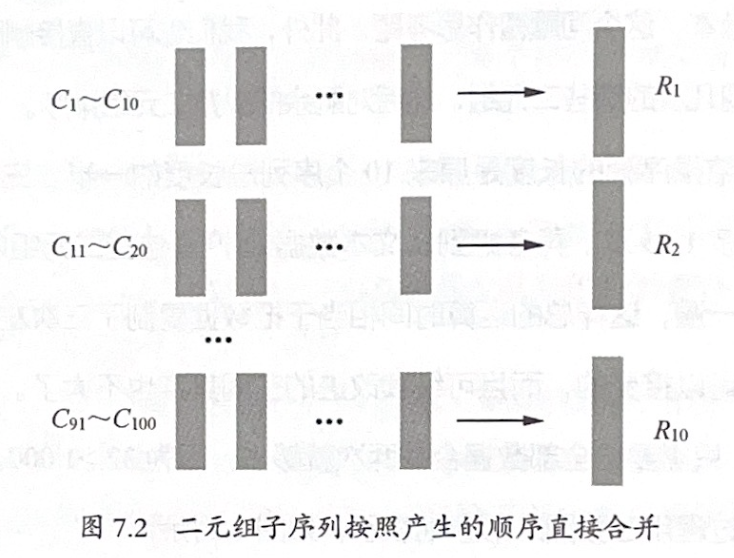
- 对各频率表排序并写入磁盘
- 归并排序合并频率表
- 使用分桶离散技术优化归并过程(按二元组首个单词分桶)
在归并时,归并的结果在同级的频率表中会有重复的二元组。如果把要归并的二元组<x,y> 中的 x 的键值为索引将二元组数据按照 x 做分桶离散,做 key 的映射,即可保证归并后集合中的二元组不会互相重复
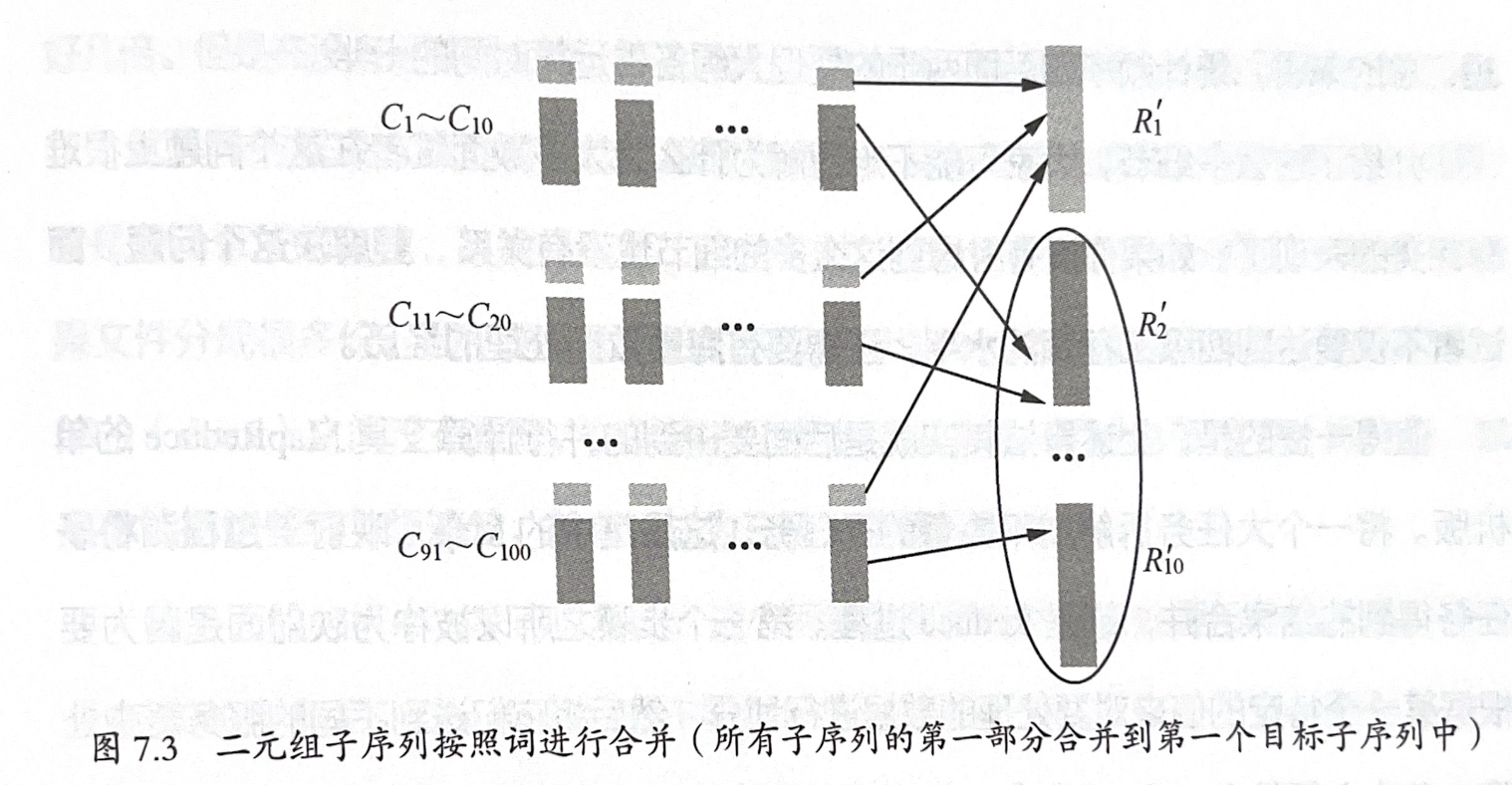
以上处理以后,只要在第三步使用中值分割算法即可求出 100 万个频率最高的二元组了
思考题7.1:并行分割查找
通过并行处理分割后的数据块,在内存中独立计算各块的频率统计,最后合并结果。
7.2 存储层次:容量与速度的平衡
存储性能三要素
- 顺序读写吞吐量
- 单次访问延迟
- 访问准备时间
存储层次详解
-
CPU架构:
- 包含ALU、FPU等单元
- 现代CPU(如i7)理论计算能力达200GB/s,但实际I/O带宽仅25GB/s
-
CPU缓存:
- L1:一级缓存 L1:64 KB,一半是指令,一半是数据。四路指令通道和八路数据通道,保证一个时间周期可以读取一个指令和两个数据。缓存未命中的概率 5% ~ 10%。
- L2:256 KB,10个时钟周期,八路通道,两个时钟周期可以提供一次数据
- L3:8 MB,所有核心共享,35 个时钟周期,16 路通道
- 访问时间与容量平方根成正比
-
内存(DRAM):
- 延迟约100周期
- 3%未命中率会导致效率降至25%:
-
硬盘:容量大2-3个数量级。访问延迟约10ms(比L1慢1000万倍)
-
云存储:适合海量数据批量处理
实际案例
- Google搜索联想词优化:通过改进缓存局部性,减少未命中,性能提升80%
- Hadoop与BigTable对比:Hadoop适合批处理,BigTable适合随机访问
思考题7.2:虚拟内存实现二元组统计
需要考虑页面置换和磁盘I/O开销,实际耗时可能比纯内存操作高1-2个数量级。
7.3 索引技术:地址与内容 P277
索引:随机访问的必要条件
- 哈希索引:O(1)查找;不支持范围查询。搜索引擎使用哈希表,但是无法查找数值范围内的信息。
- 有序索引:支持二分查找(O(log n));支持范围查询
索引的工程实现
计算机处理数值范围查询比人类想象中复杂,而模式识别(如人脸识别、声纹识别)相对简单,这反映了索引技术的本质差异。