K- Nearest Neighbor,K 近邻算法
监督学习,分类任务,计算临近度对单个数据点做分类的预测。
这是一个懒惰学习方法,意味着算法没有训练阶段,仅存储数据和标签,也称“基于内存的学习方法”。
计算目标
分为“分类任务”和“回归任务”:
- kNN 分类:根据周围的样本点,以“多数法则”给出样本分类。
- kNN 回归:根据周围样本,计算平均值作为预测值输出
算法
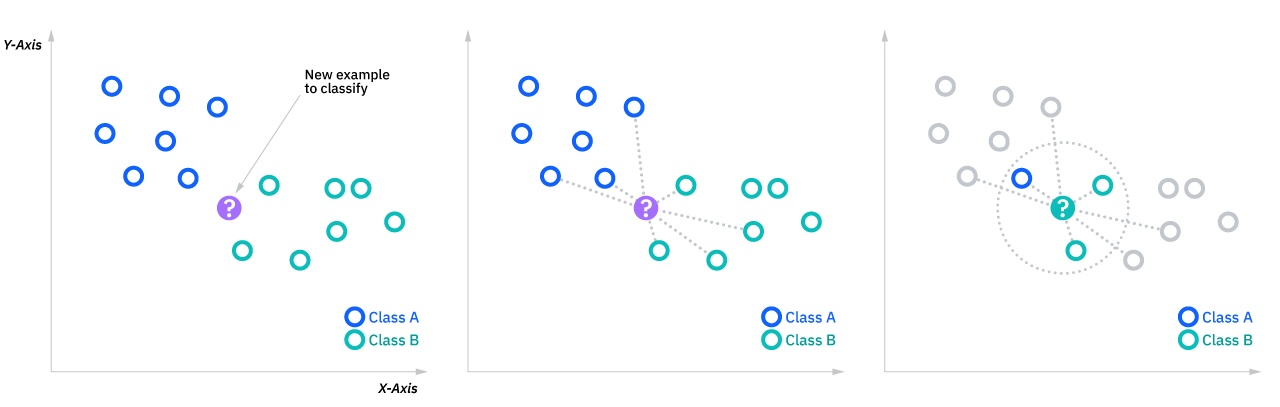
当新数据进入时,选择周边最相近的 k 个样本点,根据其类别,以“多数法则”给出样本类别点的最终结果。
距离指标:kNN 根据“距离”来判断周边的邻居是否要纳入计算范围,因此可以使用多种计算距离的方法。可见页面:相似度的计算。
局限性
kNN 在大量的数据集下,会导致计算低效,整体模型性能不佳。