上半场:强化学习RL的突破与泛化
在人工智能研究的上半场,游戏规则很明确:专注于构建新的模型和方法,而评估和基准测试则是次要的(尽管对论文发表体系是必要的)。从论文引用程度可以看出,训练和模型始终是首要任务。
That illustrates the game of the first half: focus on building new models and methods, and evaluation and benchmark are secondary (although necessary to make the paper system work).
强化学习的“配方”
强化学习(RL)被认为是AI的终点,因为它总是可以赢得游戏。传统RL框架包含三个部分:
然而研究者们长期过度关注算法而忽视环境。事实证明:
- 环境和先验比算法更重要
- 实验显示,在一个环境中的RL模型无法泛化到另一个环境
关键转折:只有GPT展现了出色的泛化能力,因为:
- 最重要的可能不是RL算法或环境,而是先验
- 这些先验可以完全通过非RL的方式获得
It turned out the most important part of RL might not even be the RL algorithm or environment, but the priors, which can be obtained in a way totally unrelated from RL.
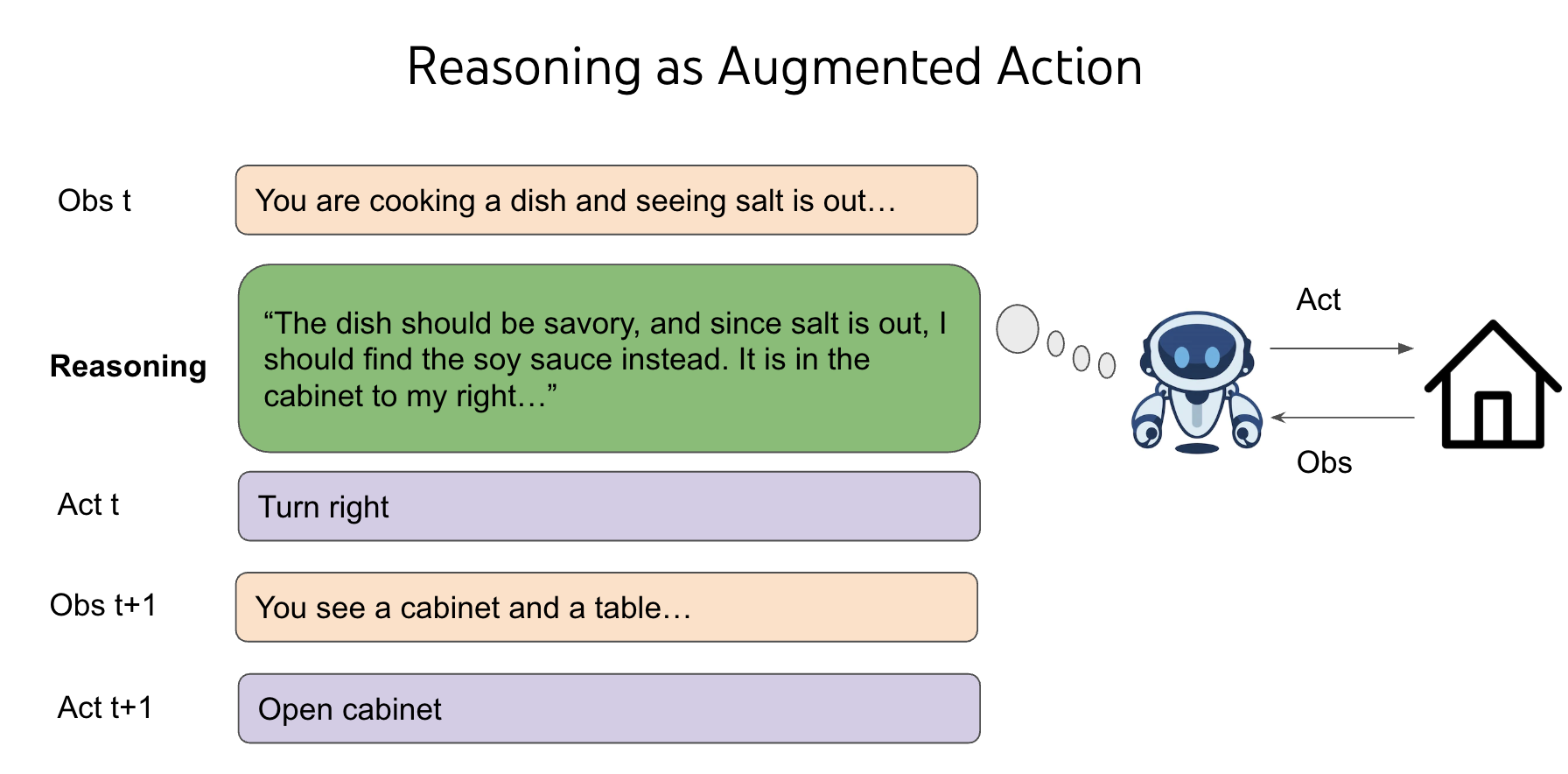
人类之所以能实现更好的泛化,是因为我们拥有丰富的常识。而推理能力让智能体能够利用语言加强对环境的认知——语言虽然不能直接改变环境,但能让智能体模拟遇到的问题。语言本身就是一种强大的泛化方法。
language generalizes through reasoning in agents.
上半场的局限
-
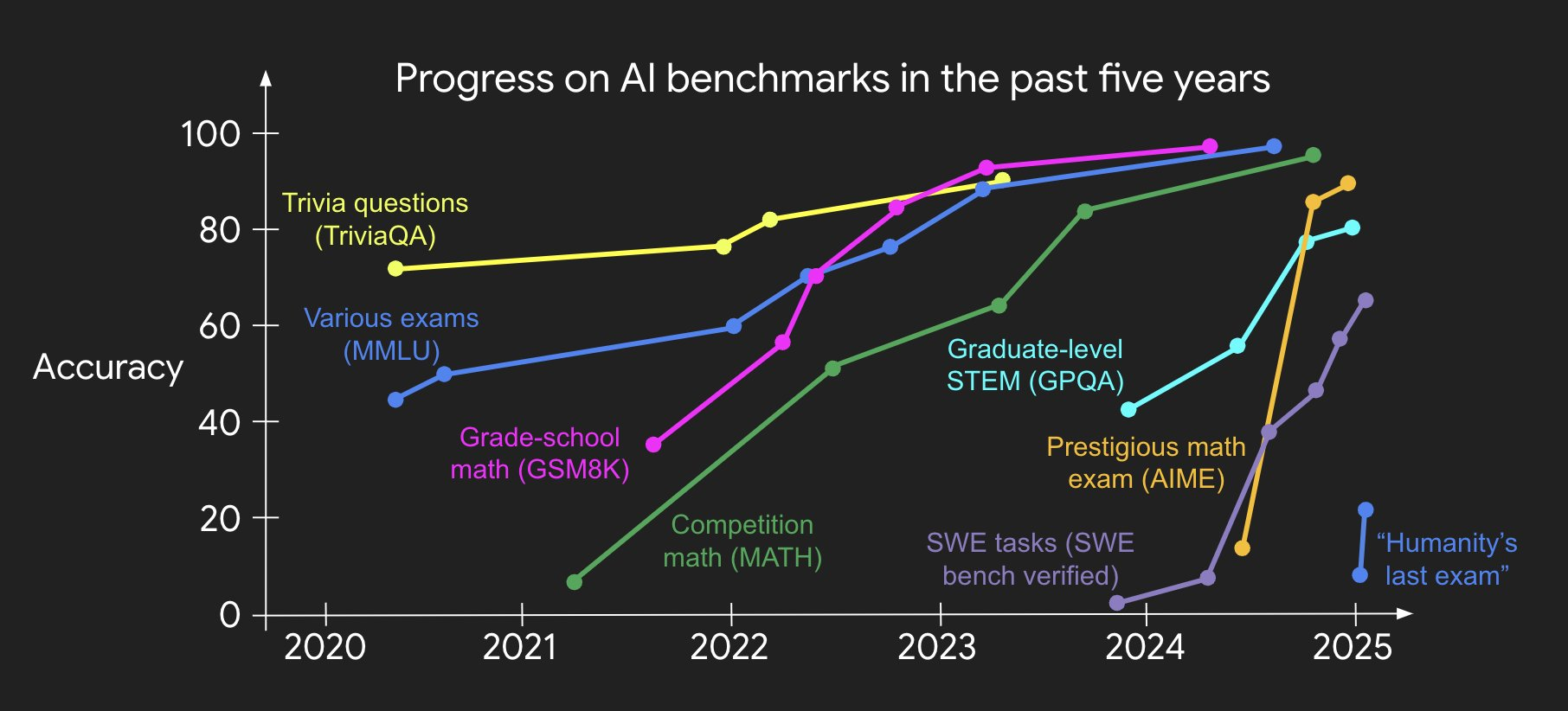
模型开发模式:构建新模型→在基准测试上提升性能
- 问题:标准化基准对性能提升的帮助不如推理能力
-
应对方式:创造更难的基准→重复上述循环
- 问题:更难的基准很快就被过拟合
下半场:解决实际问题的新范式
下半场的核心动机是重新思考评估体系。人类思维的惯性导致我们倾向于:
- 设计更难的考题
- 创造更复杂的算法题
但这些都属于“工具问题”——虽然重要,却脱离现实世界。
I call this the utility problem, and deem it the most important problem for AI.
……
our evaluation setups are different from real-world setups in many basic ways.
工具问题与现实脱节的两个例证
-
仅自主评估:
- 假设所有任务都能独立完成
- 现实情况:任务常需要与用户深度协作
-
[独立同分布]评估:
- 假设问题可以孤立解决
- 现实情况:问题通常是先后关联解决的
新游戏规则
工具问题在模型性能不足时有意义,但如今已无法有效解决现实问题。下半场需要:
- 采用更贴近现实世界的评估设置
- 开发新方法来增强之前的”配方”

展望:产品经理主导的AI新时代
随着技术成熟,产品经理将主导AI产品开发。核心问题转变为:
- “我们能训练模型解决X问题吗?”
- “我们应该训练AI做什么?如何衡量真正的进步?”
这场范式转变标志着AI从单纯追求性能指标,转向解决真实世界复杂问题的全新时代。