RAG = Retrieval-Augmented Generation
检索增强生成
数据库技术和 LLM 技术结合的产物。让 LLM 能够突破上下文的限制,处理更多的上下文内容。
数据库技术提供了带检索的存储,而 LLM 提供了对内容的处理方法。又是一个经典的“数据结构和算法”结合的典型计算机系统应用。
核心思想是将大量的文本分块,并打上标签存储到数据库,然后在用户查询时,检索相关文档并整合交给 LLM 处理,最终获得答案。
RAG 包含了计算机工程中的几种基本思想:向量化,索引,查询,分治。
标准的 RAG 技术
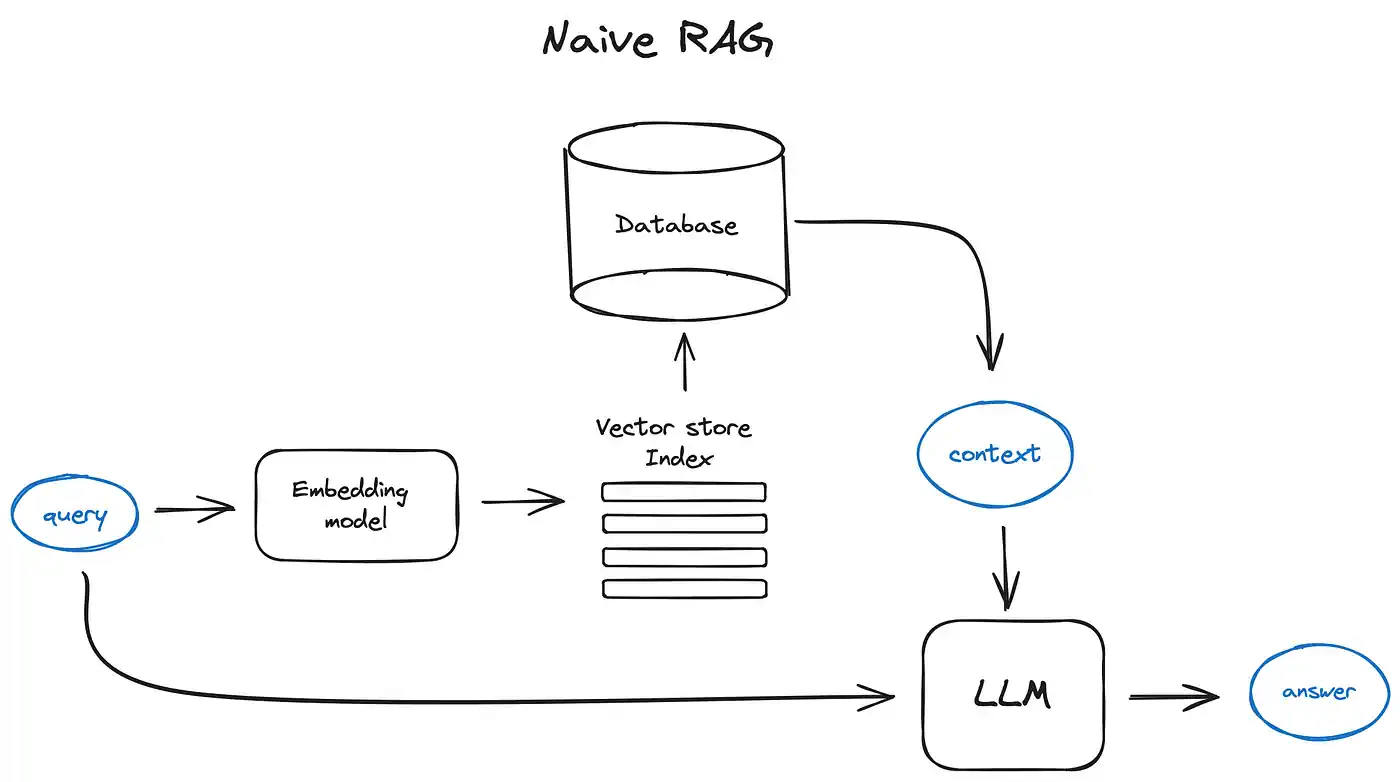
将文本预先拆分为多个索引,存放到数据库。在用户查询时,用嵌入方式将文本转换为向量,在数据库中找到相关的数据源,形成上下文交由 LLM 处理。
在这种方式中,RAG 的前置步骤只有一个嵌入过程,而没有 LLM 参与。
高级 RAG 技术
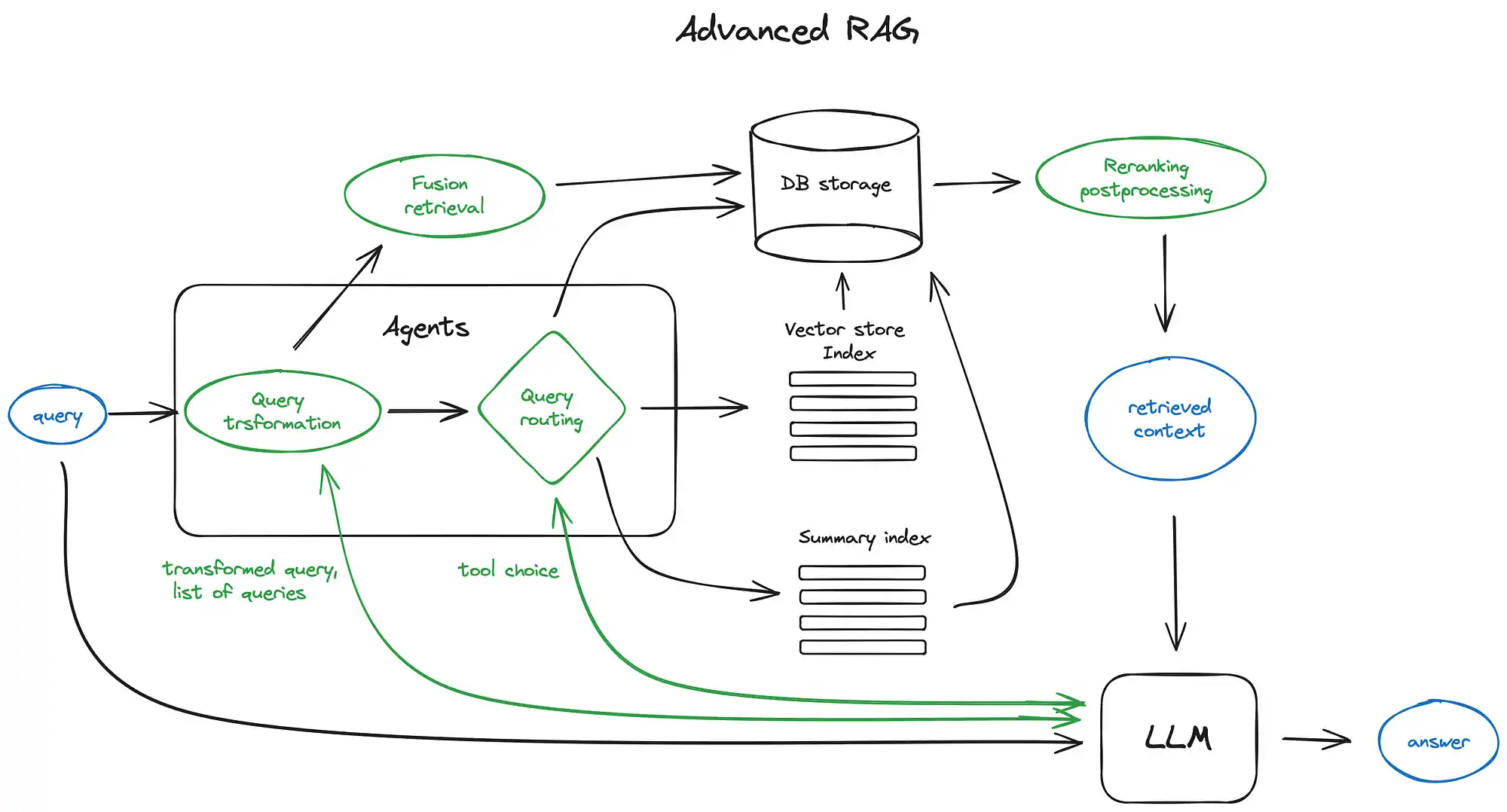
在此方法中,LLM 作为 Agent 深度参与了 RAG 过程,并对用户输入的查询请求作了一定的处理。
这种方法利用相对更加智能的方法处理了用户输入,避免用户输入的不一致性对查询结果产生的影响。
分治和向量化
在对源数据做文本处理的过程里,分治和向量化很重要,是检索的前提条件。
分治在文本处理中就是分块(Chunking),将一段长文本分成多个长度相似,语义和源文本一致的短文本。这种方法在搜索引擎中已经被广泛应用。有成熟的算法
向量化需要一个模型来处理,将单篇文章的内容转为一组向量。
索引
建立索引是检索的第一步。这一步一般是利用基于向量存储的索引方法,计算向量间的相似度建立索引。
分层索引是索引的优化方法,即为单一的文档建立两个索引,一个是表示摘要, 一个表示文档原文。
融合索引是结合了传统的关键词索引的方法和向量索引结合的混合怪。
查询变换
使用 LLM 对用户的查询做预处理,将其转换为多个子查询(Subquery)。
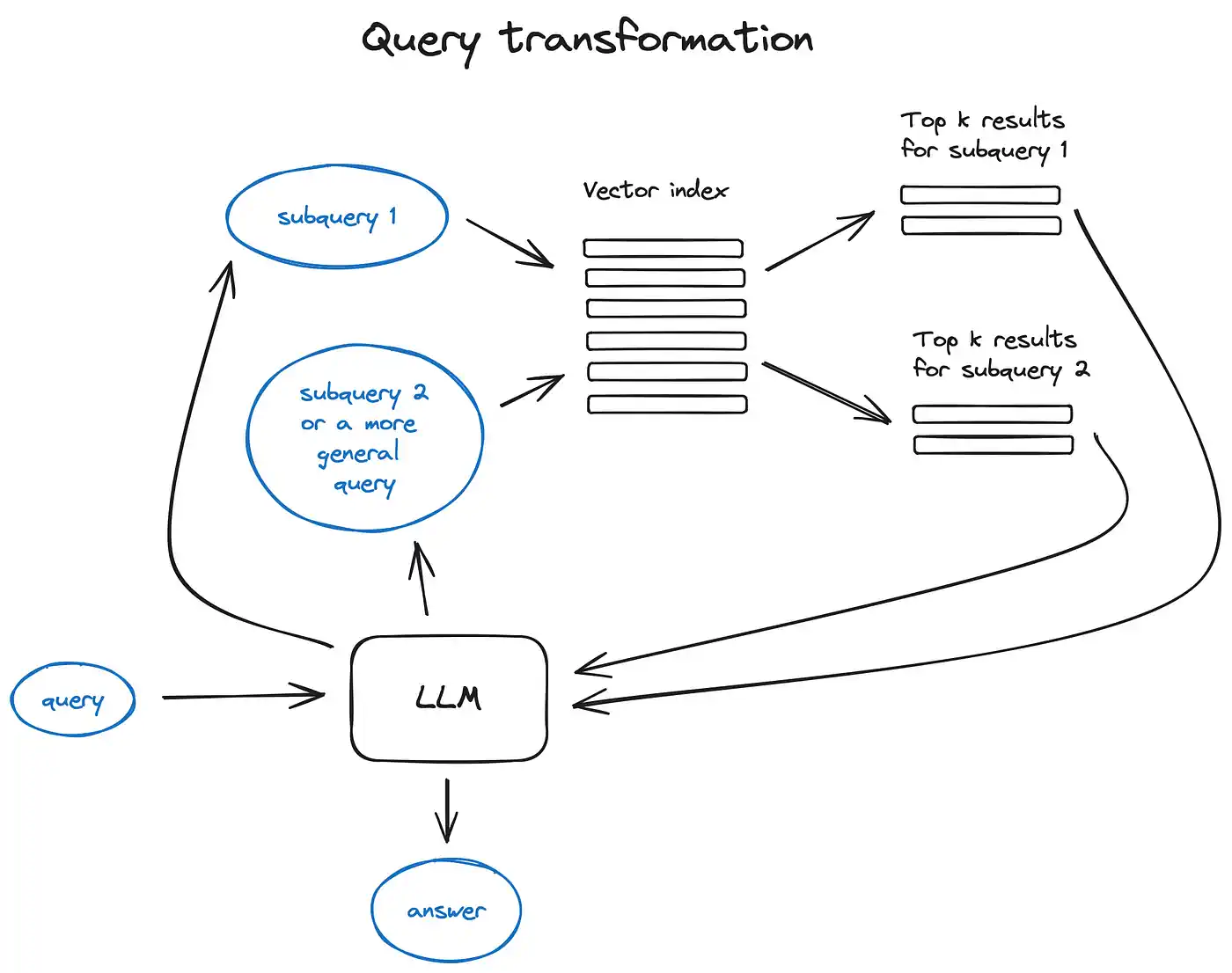
这种方法我觉得已经有点像思维链的一种应用。就像使用了思维链的 LLM 在处理用户输入时,第一件是并不是直接开始回答问题,而是对输入先做一层“反思”准备,等到对问题的理解完备之后再开始处理。只不过“查询变换”的方式是人已经定义好了 LLM 了“拆分查询请求”的任务,LLM 直接直接开始处理了。