Q学习,一种RL的算法。
目的:寻找最大化步骤奖励的期望策略。联想到MLE。
公式
三要素:
- Q 为计算目标,表示一个效用
- S 当前状态
- A 在特定 S 状态下执行的行动
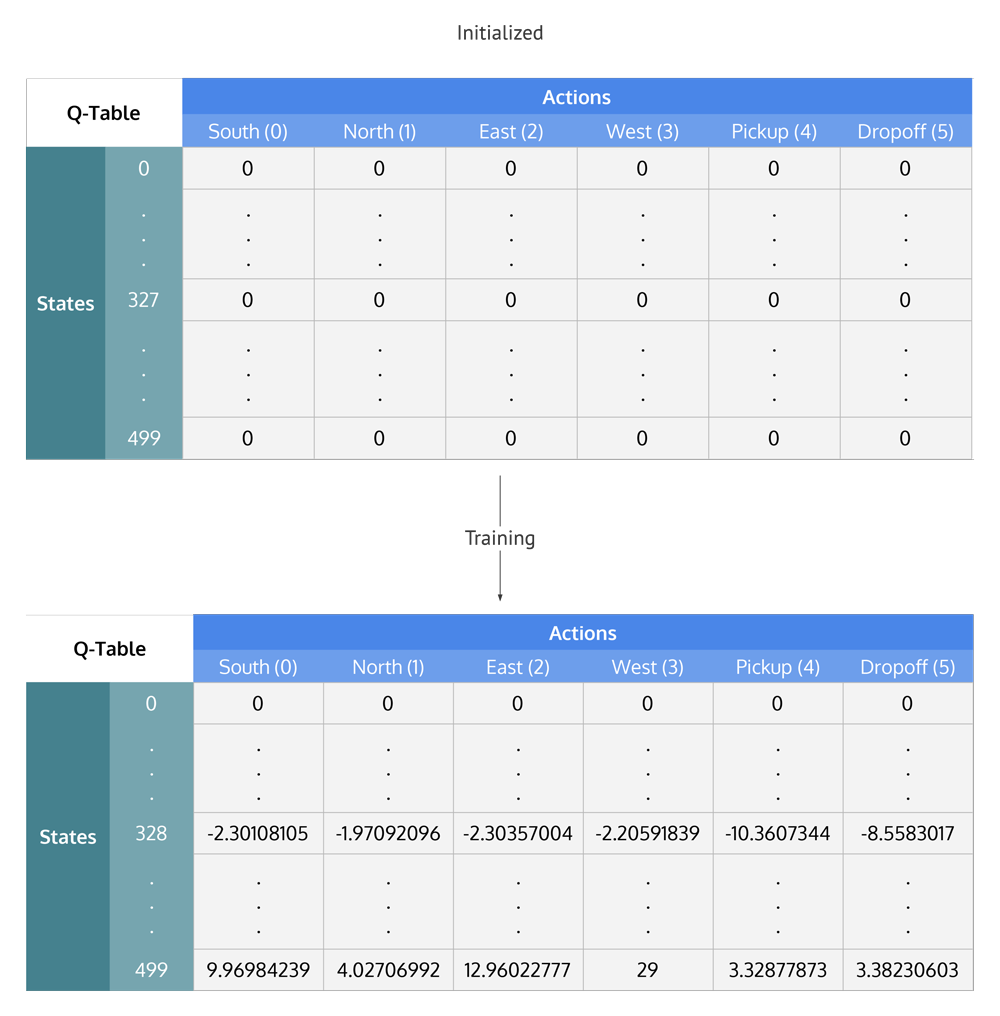
Q-Table 记录了所有 Q 在 S 和 A 下的值,表格中的内容是算法要更新的对象:
更新策略:贝尔曼方程
这是一个标准的迭代更新算法。
每一次迭代:
- 使用一个 学习率,考虑旧值的和新计算值的影响
- 表示获得的奖励,可以人为定义
- 表示查表操作,找下一个状态的所有 action 对应的 Q 的最大值。表示在当前状态的计算过程中,考虑下一步可能的效用收益。
- 算法将会进行多次迭代,在第一次迭代过程中,Q-Table 中的值均为初始值。所有 的值都为零。而在后续迭代过程中,才会有可供参考的 Q 值参与该步计算。