Bloom Filter,使用哈希映射方式,对元素作集合判定。
从底层看,实际就是对数据做有损编码,对编码做集合判定。
基本概念
ref:
布隆过滤器,可以判断一个数据是否在指定的集合内。
布隆过滤器可以对一段数据输出两种结果:
- 元素“可能”在集合内
- 元素不在集合内
数据结构:很长的二进制向量,来储存对哈希的编码。

- k 个哈希函数,每个哈希输出一个位置
训练过程(添加数据):对输入的数据,同时计算 k 个哈希。对每个哈希输出的位置,将该位置置为 1 。
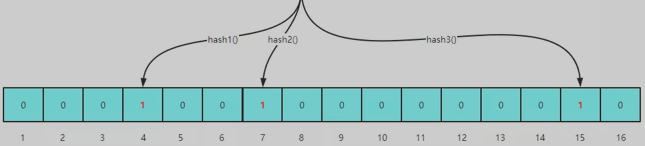
预测过程(判断数据):使用同样 k 个哈希,映射输入数据,检查哈希结果位置是否全为 1 ,如果是,则判断数据“可能”在集合内部。一旦有映射的位置为 0,那么就判断数据不在集合内部。
因为布隆过滤器的长度限制,所以可能存在误判现象,而且数组越长,误判的几率越低。
分析
预测的误判率
- m 数组长度
- k 过滤器数量
- n 已添加的元素数量
工程中可以使用的数组长度:
性质
- 计算效率极高,哈希计算速度极快,查表速度也极快
- 没有假阴性,但是有假阳性,无法 100% 确定元素是否一定在集合中
- 误判率可控
- 一旦添加元素之后,不支持删除